
机器学习教程一:K近邻算法
KNN简介
K近邻(K-Nearest Neighbors,KNN)算法是一种监督学习算法,用于分类和回归问题。它的原理相对简单,是一种基于实例的学习方法。
KNN算法的历史可以追溯到上世纪60年代。最早的形式可以追溯到Cover和Hart在1967年提出的”Nearest Neighbor Pattern Classification”论文。随后,KNN算法在机器学习领域得到了广泛的研究和应用。
使用情景

如上图所示,已知只存在蓝色矩形和空心菱形两种类别,黄色圆圈属于它们中的一个,那么判断黄色圆圈属于哪一种类别呢,这个时候就可以用到KNN算法,最基本的方式就是计算黄色圆圈距离哪个类别近,就说明黄色圆圈属于哪一类。有点类似“物以类聚,人以群分”的含义。
KNN原理
KNN算法(K-Nearest Neighbors)是一种基于实例的监督学习算法,其原理是通过找到最接近目标实例的K个邻居来进行分类。
当我们使用K最近邻(KNN)算法进行分类时,需要遵循下面步骤:
- 准备训练数据集:我们首先需要一个带有标签的训练数据集。每个样本都有一组特征和相应的标签,用于表示样本的属性和类别。
- 计算距离:对于一个新的未标记样本,我们需要计算它与训练集中每个样本的距离。通常使用欧氏距离或其他距离度量方法来衡量样本之间的相似性或距离。
- 选择最近的K个邻居:KNN算法中的K是一个超参数,表示在预测新样本时要考虑的最近邻居的数量。我们需要选择一个合适的K值,它会影响预测结果的准确性。根据计算得到的距离,选择与新样本最近的K个邻居。
- 类别决策:对于分类问题,KNN算法采用”多数表决”的方式决定新样本所属的类别。即,根据K个最近邻居的标签进行投票,得票最多的类别将被预测为新样本的类别。根据投票结果,确定新样本的类别。
我们按照上面步骤做一个示例。
1.准备训练数据集
下面是一个简单的KNN数据集示例,其中包含了一些特征和对应的类别标签:
| 特征1 | 特征2 | 类别标签 |
|---|---|---|
| 5.1 | 3.5 | A |
| 4.9 | 3.0 | A |
| 6.7 | 3.1 | B |
| 6.0 | 3.0 | B |
| 5.5 | 2.8 | B |
在这个示例中,我们使用两个特征(特征1和特征2)来描述每个样本。每个样本还有一个类别标签(A或B),表示样本所属的类别。
例如,第一行的样本具有特征1值为5.1、特征2值为3.5,以及类别标签A。第三行的样本具有特征1值为6.7、特征2值为3.1,以及类别标签B。
使用numpy创建数据,代码展示:
import numpy as np
def createDatabse():
xTrain=np.array([[5.1, 3.5],
[4.9, 3.0],
[6.7, 3.1],
[6.0, 3.0],
[5.5, 2.8]])
yTrain=np.array(['A', 'A', 'B', 'B', 'B'])
return xTrain,yTrain
if __name__ == '__main__':
createDatabse()2.计算距离
首先创建一个未标记的样本,例如[5.7, 3.2],然后用来计算该样本和其他训练集样本的距离,常见的衡量距离有欧氏距离(Euclidean Distance)、曼哈顿距离(Manhattan Distance)、闵可夫斯基距离(Minkowski Distance)、切比雪夫距离(Chebyshev Distance)、余弦相似度(Cosine Similarity)。这里我们使用欧式距离来计算样本之间的距离。距离计算公式见附录。
欧氏距离是常用表示距离的方式,在同一空间的两点之间的距离又叫做欧式距离。
在二维空间中,对于点A(x1,y1)和点B(x2,y2)之间的距离是:
在多维空间中,对于点A(x1,y1,z1,……)和点B(x2,y2,z2,……)之间的距离是:
在上面计算过程中,x、y表示特征数量,下标1和2表示这不同的类别。可以给出下面代码计算未标记样本和数据集的距离。
import math
def createDatabse():
xTrain = [[5.1, 3.5],
[4.9, 3.0],
[6.7, 3.1],
[6.0, 3.0],
[5.5, 2.8]]
yTrain=['A', 'A', 'B', 'B', 'B']
return xTrain,yTrain
# 计算点之间的欧几里得距离
def enclideanDistance(x1, x2):
distance = 0
for i in range(len(x1)):
distance += pow((x1[i] - x2[i]), 2)
return math.sqrt(distance)
# knn算法
def knn(xTrain,yTrain, x_test):
# 计算距离
distances = []
for i in range(len(xTrain)):
dist = enclideanDistance(xTrain[i], x_test)
distances.append((i, dist))
# 根据距离排序
distances.sort(key=lambda x: x[1])
if __name__ == '__main__':
createDatabse()
xTest = [5.7, 3.2]
3.选择最近的k个邻居
选择前k个最近的邻居,对knn算法做出下面修改。增加了一个参数k和局部变量neighbors。
def knn(xTrain,yTrain, x_test, k):
# 计算距离,二维数组,一维度表示训练集下标,二维度表示距离
distances = []
for i in range(len(xTrain)):
dist = enclideanDistance(xTrain[i], x_test)
distances.append((i, dist))
# 根据距离排序
distances.sort(key=lambda x: x[1])
# 得到前k个邻居,一维度表示
neighbors = distances[:k]4.类别决策
import math
# 创建训练数据集
def createDatabse():
xTrain = [[5.1, 3.5],
[4.9, 3.0],
[6.7, 3.1],
[6.0, 3.0],
[5.5, 2.8]]
yTrain = ['A', 'A', 'B', 'B', 'B']
return xTrain, yTrain
# 计算点之间的欧几里得距离
def enclideanDistance(x1, x2):
distance = 0
for i in range(len(x1)):
distance += pow((x1[i] - x2[i]), 2)
return math.sqrt(distance)
# knn算法
def knn(xTrain, yTrain, x_test, k):
# 计算距离,二维数组,一维度表示训练集下标,二维度表示距离
distances = []
for i in range(len(xTrain)):
dist = enclideanDistance(xTrain[i], x_test)
distances.append((i, dist))
# 根据距离排序
distances.sort(key=lambda x: x[1])
# 得到前k个邻居,一维度表示训练集的下标,二维度表示距离
neighbors = distances[:k]
# 统计邻居所属类别
counts = {}
for neighbor in neighbors:
label = yTrain[neighbor[0]]
# dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值
counts[label] = counts.get(label, 0) + 1
# 对counts进行降序排列
sortedCount = sorted(counts.items(), key=lambda x: x[1], reverse=True)
return sortedCount[0][0]
if __name__ == '__main__':
xTrain, yTrain = createDatabse()
xTest = [5.7, 3.2]
yTest=knn(xTrain=xTrain, yTrain=yTrain, x_test=xTest, k=3)
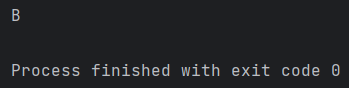
print(yTest)
得到结果,可以看到测试样本属于B类别。
KNN核心
k值选择
在K最近邻(K-Nearest Neighbors,KNN)算法中,k值是一个重要的超参数,它决定了在进行分类时考虑的最近邻的数量。k值的选择会直接影响KNN算法的性能和结果。
- 预测的偏差与方差:较小的k值会导致较低的偏差但较高的方差,因为模型更容易受到局部特征的影响。较大的k值会导致较高的偏差但较低的方差,因为模型更倾向于使用整体特征进行预测。因为较大的k值会收集到远距离的数据点,导致分类错误。
- 计算效率:较小的k值意味着需要考虑更多的最近邻点,计算的复杂度更高。因此,在实际应用中,选择较小的k值可能会增加算法的计算成本。较大的k值可能会降低计算成本,但可能会导致更多的内存消耗。
- 样本不平衡问题:当数据集中的类别分布不平衡时,选择适当的k值非常重要。较小的k值可能对少数类别的分类效果不好,而较大的k值可能更容易受到多数类别的影响。因此,在处理样本不平衡问题时,需要根据具体情况选择合适的k值。
根据1,我们可以看到我们不能选择一个大值,但是根据3,我们又可以看到一个很小的值也是不可以的。在应用中一般选择较小的数值,可以通过交叉验证来选择出合适的k值。
优势与劣势
优势:
- 简单易理解:KNN算法是一种直观且易于理解的算法。它的基本思想是基于邻居的投票或平均值来进行预测,没有复杂的数学推导或假设。
- 适用于多类别问题:KNN算法可以直接应用于多类别分类问题,而不需要进行额外的修改或调整。
- 对异常值和噪声相对鲁棒:KNN算法在少量异常值或噪声存在的情况下表现较好,因为它基于邻居的投票或平均值,可以通过多个邻居的一致性来减少异常值的影响。
- 无需训练阶段:KNN算法是一种懒惰学习(lazy learning)算法,它在训练阶段不需要进行显式的模型训练,只需存储训练数据。这意味着可以更快地进行预测,而不需要花费时间用于训练。
劣势:
- 计算复杂度高:KNN算法需要计算测试样本与所有训练样本之间的距离,并找到最近的K个邻居。随着训练集的增大,计算复杂度会显著增加,这可能导致较慢的预测速度。这一点和优势4相对应。
- 需要选择合适的K值:KNN算法的性能高度依赖于选择合适的K值。选择较小的K值可能导致过拟合,选择较大的K值可能导致欠拟合。选择合适的K值需要通过交叉验证等技术进行调优。
- 类别不平衡问题:当训练集中的类别不平衡时,KNN算法可能偏向于多数类别,对少数类别的分类效果较差。在处理类别不平衡问题时,需要采取额外的措施来平衡类别权重。
附录
欧氏距离
欧氏距离是常用表示距离的方式,在同一空间的两点之间的距离又叫做欧式距离。
在二维空间中,对于点A(x1,y1)和点B(x2,y2)之间的距离是:
在多维空间中,对于点A(x1,y1,z1,……)和点B(x2,y2,z2,……)之间的距离是:
在上面计算过程中,x、y表示特征数量,下标1和2表示这不同的类别。
曼哈顿距离
曼哈顿距离是一种用于测量在规则网格上的两个点之间的距离的方法。它得名于曼哈顿(Manhattan)的城市布局,因为在曼哈顿街区中,通过街道网格行进需要按照直角转弯,而曼哈顿距离正是计算在规则网格中按照直角行进的距离。
原理:曼哈顿距离是通过将两个点的横坐标差的绝对值与纵坐标差的绝对值相加得到的。
在二维空间中,假设有两个点A(x1, y1)和B(x2, y2),则它们之间的曼哈顿距离(d)可以表示为:
其中,|x1 – x2| 表示点A和点B在横坐标上的差的绝对值,|y1 – y2| 表示点A和点B在纵坐标上的差的绝对值。
在n维空间中,假设有两个点A(x1,y1,z1……)和B(x2,y2,z2……),则它们的曼哈顿距离(d)可以表示为:
代码:
def manhattanDistance(x1, x2):
distance = 0
for i in range(len(x1)):
distance += abs(x1[i] - x2[i])
return distance切比雪夫距离
切比雪夫距离也称为棋盘距离,是一种用于测量向量空间中两个点之间的距离的度量方法。它是曼哈顿距离的一种特例,适用于多维空间中的距离计算。
原理:切比雪夫距离是通过计算两个点在每个维度上差值的最大值来得到的。假设有两个点A(x1, y1,z1,……)和B(x2, y2,z2,……),其切比雪夫距离(d)可以表示为:
其中,|x1 – x2| 表示点A和点B在横坐标上的差的绝对值,|y1 – y2| 表示点A和点B在纵坐标上的差的绝对值。切比雪夫距离即为两个差值绝对值的最大值。
代码:
def chebyshevDistance(x1, x2):
distance = max(abs(x1[i] - x2[i]) for i in range(len(x1)))
return distance闵可夫斯基距离
闵可夫斯基距离(Minkowski Distance)是一种用于测量向量空间中两个点之间的距离的度量方法。它是曼哈顿距离和欧氏距离的一般化形式,可以根据参数p的不同取值,得到不同的距离度量。
def minkowskiDistance(x1, x2, p):
distance = 0
for i in range(len(x1)):
distance += abs(x1[i] - x2[i]) ** p
return distance ** (1/p)我们可以发现当参数p等于1时,就是所说的曼哈顿距离;当参数p等于2时,就是欧氏距离;我们也可以发现当p趋向于无穷大的时候,距离d就是各个维度差最大的值,也就是切比雪夫距离。
余弦相似度
余弦相似度(Cosine Similarity)是一种用于比较两个向量相似性的度量方法。它基于向量之间的夹角来衡量它们的相似程度,而不考虑向量的绝对大小。
原理:余弦相似度通过计算两个向量的内积与它们的模长的乘积的比值来确定它们的相似度。
假设有两个向量A和B,其余弦相似度(similarity)可以表示为:
import numpy as np
def cosineSimilarity(x1, x2):
dotProduct = np.dot(x1, x2)
normx1 = np.linalg.norm(x1)
normx2 = np.linalg.norm(x2)
similarity = dotProduct / (normx1 * normx2)
return similarity其中,A · B表示向量A和向量B的内积(点积),|A|和|B|表示向量A和B的模长(范数)。θ表示向量A和向量B之间的夹角。
余弦相似度的取值范围为[-1, 1],其中1表示完全相似,-1表示完全不相似,0表示无关。
参考链接
1.理论部分参考《统计学习方法》李航





