
机器学习教程十:贝叶斯实现文本分类
sklearn.naive_bayes: Naive Bayes
官网链接如下图所示:朴素贝叶斯基于条件独立的假设前提,有五个不同的算法,适用于不同的情况。

- BernoulliNB:多变量伯努利模型的朴素贝叶斯分类器,先验为伯努利分布的朴素贝叶斯。如果特征向量是二进制(即0和1),那这个模型是非常有用的。不同于多项式,伯努利把出现多次的词语视为只出现一次,更加简单方便。
- CategoricalNB:分类特征的朴素贝叶斯分类器。该分类器适用于具有离散分类特征的数据集。它假设每个特征的可能取值是已知的离散类别,特征之间相互独立。该算法可以处理离散的计数数据,如一些自然语言处理任务中的特征。
- ComplementNB:Complement朴素贝叶斯分类器,由Rennie等人在2003年提出。该分类器是对标准朴素贝叶斯算法的改进。它通过考虑非目标类别的补集来提高分类性能。这对于不平衡类别分布的问题特别有效。
- GaussianNB:高斯朴素贝叶斯分类器(GaussianNB),先验为高斯分布的朴素贝叶斯。它假设每个类别的特征值是从高斯分布中独立采样得到的。在实践中,它通常用于连续数值特征的分类问题。
- MultinomialNB:多项式模型的朴素贝叶斯分类器,先验为多项式分布的朴素贝叶斯,如文本分类中的单词计数。它假设特征是从多项式分布中独立采样得到的。用于离散计数。如一个句子中某个词语重复出现,我们视它们每个都是独立的,所以统计多次,概率指数上出现了次方。
伯努利分类器
我们以伯努利分类器为例,看一下函数。伯努利假设特征的先验概率为多项式分布,即:
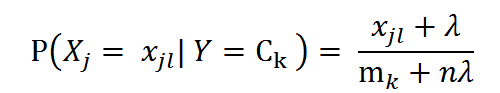
其中, P(Xj = Xjl | Y = Ck)是第k个类别的第j维特征的第l个取值条件概率。mk是训练集中输出为第k类的样本个数。λ为一个大于0的常数,常常取值为1,即拉普拉斯平滑,也可以取其他值。
参数
- alpha:平滑参数,默认为1.0。平滑是为了解决在训练数据中可能出现的零概率问题。通过增加alpha值,可以在计算概率时引入一定程度的平滑,避免出现概率为零的情况。当alpha设置为0且force_alpha=True时,不进行平滑。
- force_alpha:布尔值,默认为True。如果设置为False且alpha小于1e-10,会将alpha值设置为1e-10。如果设置为True,则保持alpha值不变。这样做可能会导致数值计算错误,如果alpha值与0非常接近。
- binarize:阈值参数,用于将样本特征二值化(映射为布尔值)。如果为None,则假定输入已经是二进制向量。可以根据具体情况设置不同的阈值,将连续特征二值化为布尔特征。
- fit_prior:布尔值,默认为True。指示是否学习类别的先验概率。如果设置为False,将使用均匀先验概率。
- class_prior:类别的先验概率,形状为(n_classes,)的数组,默认为None。如果指定了先验概率,则不会根据数据进行调整。可以通过设置先验概率来对不同类别进行先验偏好。
方法
- fit(X, y, sample_weight=None):根据给定的训练数据X和对应的标签y,拟合朴素贝叶斯分类器模型。可选地,可以提供样本权重sample_weight来调整不同样本的重要性。
- get_metadata_routing():获取该对象的元数据路由信息。
- get_params(deep=True):获取该估计器的参数。
- partial_fit(X, y, classes=None, sample_weight=None):对一批样本进行增量拟合。该方法可以用于增量学习,适用于大规模数据集或流式数据。
- predict(X):对给定的测试向量X进行分类预测,返回预测结果。
- predict_joint_log_proba(X):返回测试向量X的联合对数概率估计。
- predict_log_proba(X):返回测试向量X的对数概率估计。
- predict_proba(X):返回测试向量X的概率估计。
- score(X, y, sample_weight=None):返回给定测试数据和标签的平均准确率。
- set_fit_request(*, sample_weight=None):设置传递给fit方法的元数据请求。
- set_params(**params):设置该估计器的参数。
- set_partial_fit_request(*, classes=None, sample_weight=None):设置传递给partial_fit方法的元数据请求。
- set_score_request(*, sample_weight=None):设置传递给score方法的元数据请求。
常用的方法:ft(),predict(),predict_proba(),score()。
贝叶斯分类器识别数字
依然选择mnist数据集,这个数据集已经用很多次了,直接展示代码。
'''
@File : naiveBayes1.py
@Contact : zhangzhilong2022@gmail.com
@Modify Time 2024/3/8 10:48
@Author huahai2022
@Desciption
'''
from matplotlib import pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB,MultinomialNB
from sklearn.metrics import accuracy_score
# 加载MNIST数据集
digits = datasets.load_digits()
X = digits.data
print(X.shape)
y = digits.target
print(y.shape)
plt.imshow(X[0].reshape(8, 8),cmap='gray')
plt.show()
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#创建高斯贝叶斯分类器
model = MultinomialNB()
model.fit(X_train, y_train)
#预测分类结果
prediction=model.predict(X_test)
print(f"分类准确率为{accuracy_score(y_test,prediction)}")
这里我们先选择多项式分类器,得到的准确率为91%,使用高斯分类器得到的结果大概为84%,也可以使用其它的分类器,不同分类器适用不同分类任务,多尝试。
朴素贝叶斯文本分类问题
数据集介绍
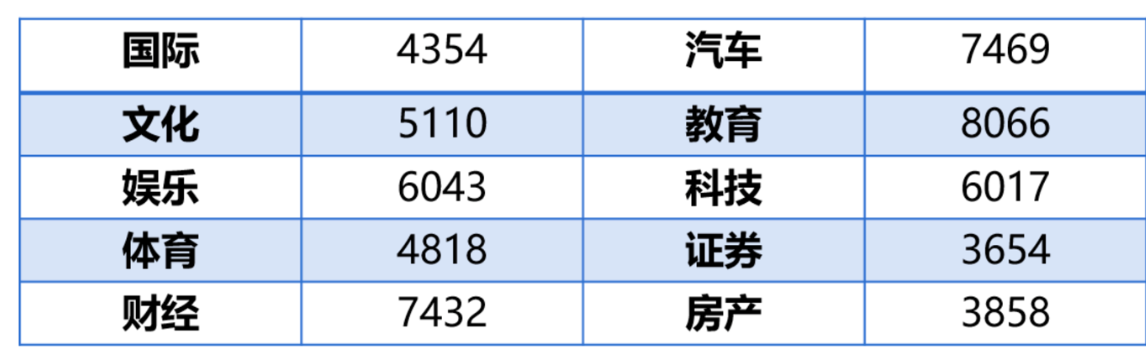
从中文新闻网站上爬取56821条新闻摘要数据,数据集中包含10个类别,本次实践将其中90%作为训练集,10%作为验证集

分词
我们可以看到标签在句子中间,先获取文本内容和标签,然后适用结巴分词把文本内容分成词语。给出下面的代码。
'''
@File : naiveBayes2.py
@Contact : zhangzhilong2022@gmail.com
@Modify Time 2024/3/8 11:04
@Author huahai2022
@Desciption
'''
import jieba
import re
def text_to_words(file_path):
'''
分词
return:sentences_arr, lab_arr
'''
sentences_arr = []
lab_arr = []
with open(file_path,'r',encoding='utf8') as f:
for line in f.readlines():
lab_arr.append(line.split('_!_')[1]) #得到标签
sentence = line.split('_!_')[-1].strip() #得到句子
sentence = re.sub("[s+.!/_,$%^*(+"')]+|[+——()?【】“”!,。?、~@#¥%……&*()《》:]+", "",sentence) #去除标点符号
sentence = jieba.lcut(sentence, cut_all=False) #切分句子
sentences_arr.append(sentence)
return sentences_arr, lab_arr
#获取分词后的数据及标签
sentences_arr, lab_arr = text_to_words('D:project\tutorial机器学习code\Naive Bayes\news_classify_data.txt')
print(sentences_arr[:5])
这样我们成功的获取了标签,并对句子进行了分词。我们查看前5行内容。
[['老祖宗', '俗语', '万恶', '淫', '为首', '下', '一句', '更是', '精华', '却', '没', '几个', '人能', '做到'], ['老照片', '1907', '年', '山东省', '泰安', '府'], ['亦', '舒', '经典语录', '100', '句'], ['乐山', '大佛', '整修', '完成', '花脸', '被', '清洗', '干净', '网友', '美', '完容', '变帅', '了'], ['7000', '年前', '的', '女子', '正值', '花样年华', '为何', '遭受', '到', '此', '残忍', '的', '对待']]句子已经完成了划分。
生成词典
我们在统计词频,获取词语特征之前,我们想一下,有一些词对我们是没有用的,比如说”了”“的”,我们不能对它进行分类到任何一个类别,所以我们在统计词频之前要把它去除。有一个停用词列表,大致内容如下,我们需要对它进行加载。
适用下面的代码对停用词进行加载。
def load_stopwords(file_path):
'''
创建停用词表
参数 file_path:停用词文本路径
return:停用词list
'''
stopwords = [line.strip() for line in open(file_path, encoding='UTF-8').readlines()]
return stopwords
#加载停用词
stopwords = load_stopwords('data/data43470/stopwords_cn.txt')我们下一步对数据集中的停用词进行删除,然后对词语出现的次数进行统计。给出下面的代码。
def get_dict(sentences_arr,stopswords):
'''
遍历数据,去除停用词,统计词频
return: 生成词典
'''
word_dic = {}
for sentence in sentences_arr:
for word in sentence:
if word != ' ' and word.isalpha():
if word not in stopswords:
word_dic[word] = word_dic.get(word,1) + 1
word_dic=sorted(word_dic.items(),key=lambda x:x[1],reverse=True) #按词频序排列
return word_dic
# 生成词典
word_dic = get_dict(sentences_arr,stopwords)查看一下生成结果

可以看到成功统计出了词频。我们并不需要那么多个词典,我们选择前10000个生成特征词列表。给出下面的代码:
def get_feature_words(word_dic,word_num):
'''
从词典中选取N个特征词,形成特征词列表
return: 特征词列表
'''
n = 0
feature_words = []
for word in word_dic:
if n < word_num:
feature_words.append(word[0])
n += 1
return feature_words
#生成特征词列表
feature_words = get_feature_words(word_dic,10000)这样我们选择了前10000个出现频率多的词语作为特征词
生成特征向量
我们先按照8:2的比例将数据集切分为训练集和测试集
#数据集划分
train_data_list, test_data_list, train_class_list, test_class_list = model_selection.train_test_split(sentences_arr, lab_arr, test_size=0.2)我们的数据集是一个个文本,我们需要将他们向量化。向量化的方式是,如果出现了特征词中的词语在特征词位置记为1.
# 文本特征
def get_text_features(train_data_list, test_data_list, feature_words):
'''
根据特征词,将数据集中的句子转化为特征向量
'''
def text_features(text, feature_words):
text_words = set(text)
features = [1 if word in text_words else 0 for word in feature_words] # 形成特征向量
return features
train_feature_list = [text_features(text, feature_words) for text in train_data_list]
test_feature_list = [text_features(text, feature_words) for text in test_data_list]
return train_feature_list, test_feature_list
train_feature_list,test_feature_list = get_text_features(train_data_list,test_data_list,feature_words)我们展示前5个样本查看,每个样本都是1万长度,1代表含有特征词,0表示没有。
构建分类器
对于文本词频统计,适合适用多项式分类器,使用拉普拉斯平滑,给出下面的代码。至此,工作结束。
from sklearn.metrics import accuracy_score,classification_report
#获取朴素贝叶斯分类器
classifier = MultinomialNB(alpha=1.0, # 拉普拉斯平滑
fit_prior=True, #否要考虑先验概率
class_prior=None)
#进行训练
classifier.fit(train_feature_list, train_class_list)
# 在验证集上进行验证
predict = classifier.predict(test_feature_list)
test_accuracy = accuracy_score(predict,test_class_list)
print("accuracy_score: %.4lf"%(test_accuracy))
print("Classification report for classifier:n",classification_report(test_class_list, predict))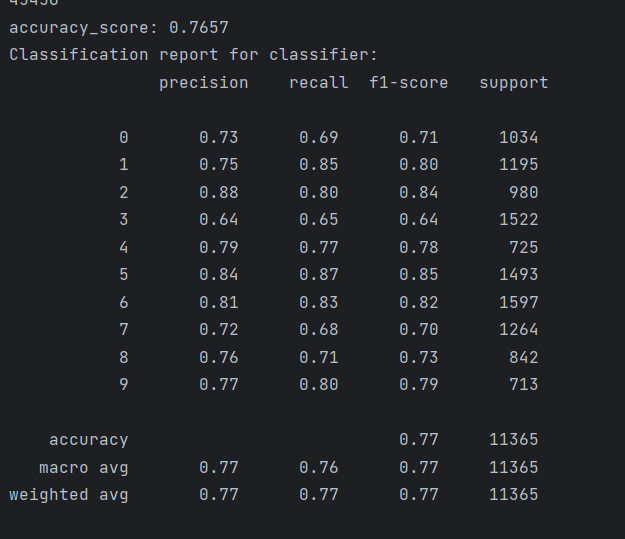
可以看到准确率大致为77%
完整代码见仓库






1 Response