
计算机视觉五:目标检测概述
目标检测概述
目标检测就是在给定的图片中准确找到物体的所在位置,并标注出物体的类别。
问题的难点在于:物体的尺寸变化范围很大,摆放物体的角度、姿态不定,而且可以出现在图片的任何地方,更何况物体还可以是多个类别。
那么这样看起来目标检测就相当于定位加分类。(可爱猫猫)

目标检测发展历程
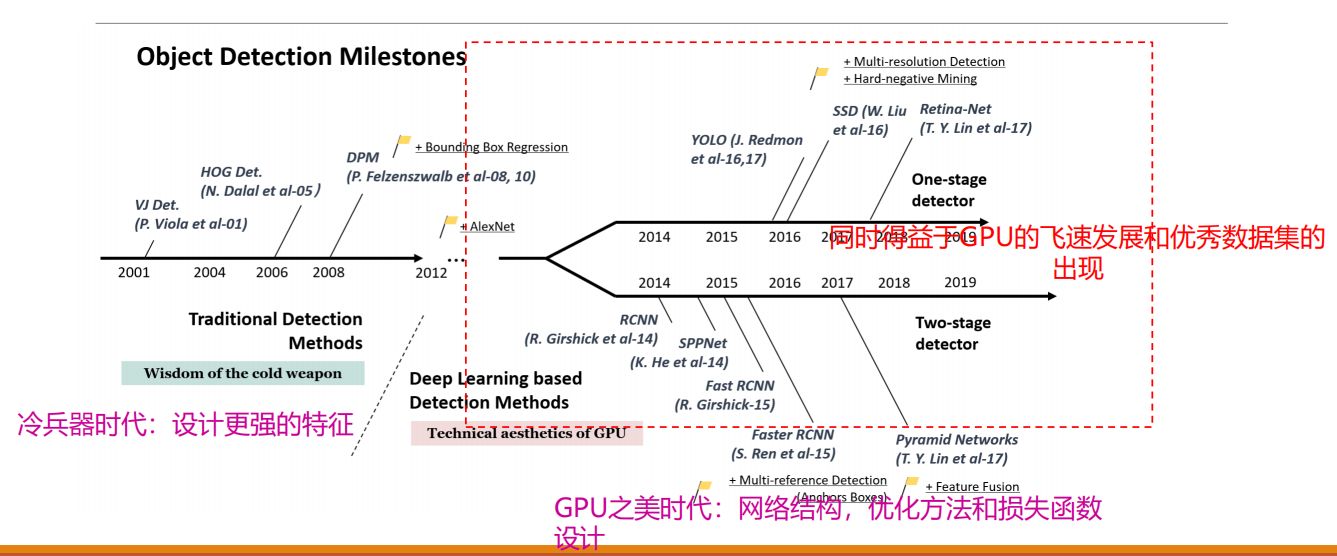
从设计更强的特征到设计更加强大的网络架构,优化方法、损失函数。
目标检测数据集



深度学习下的目标检测
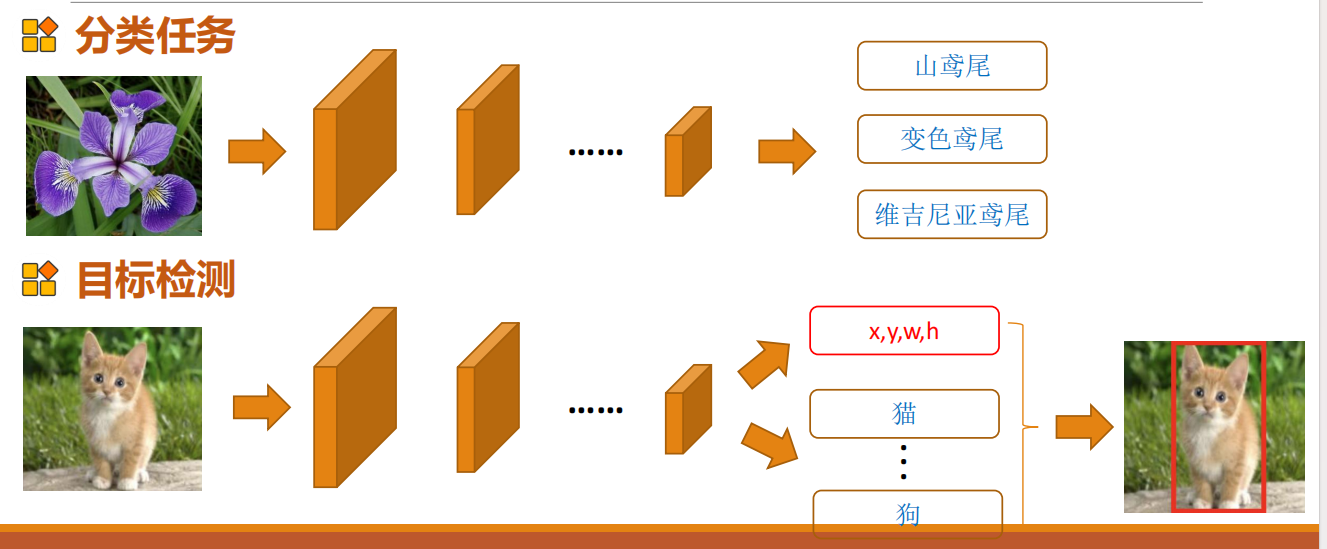
相当于增加了一个边框用来确定待识别物体的位置
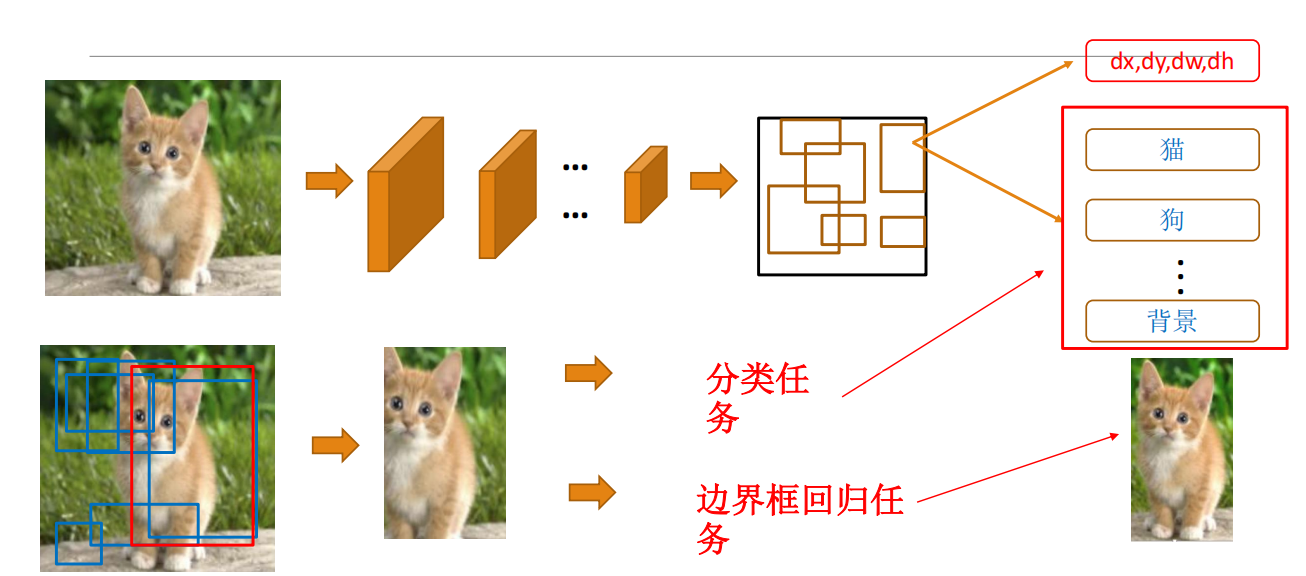
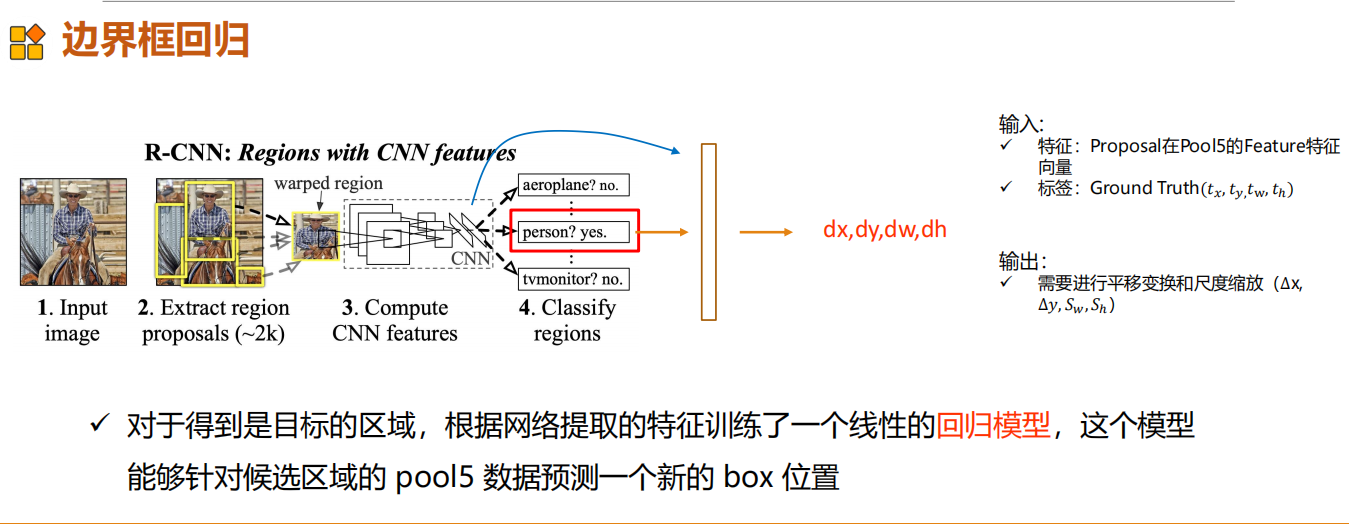
边界框回归
通过学习一种映射关系,对目标候选的位置进行精化(Refine)。
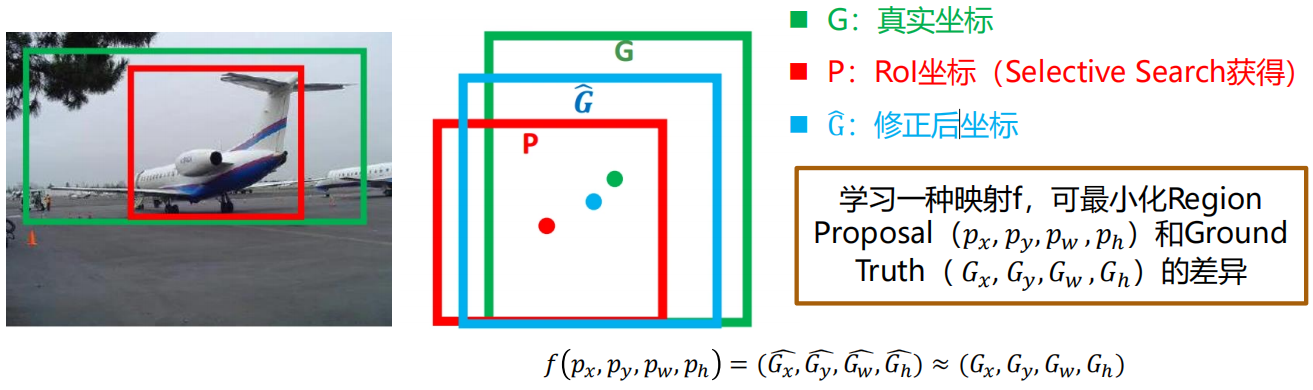
通过使用IOU来衡量真实标注和预测结果的重合程度。

通过非极大值抑制消除冗余的检测框。

- 对所有的候选框按照置信度分数进行排序,从高到低。
- 选择置信度最高的候选框,并将其加入最终输出列表中。
- 对剩余的候选框进行遍历,计算当前候选框与已选择的框的重叠度(如交并比)。
- 如果当前候选框与任何已选择的框的重叠度大于预先设定的阈值,则将其移除;否则,将其加入最终输出列表中。
- 重复步骤 3 和步骤 4,直到遍历完所有的候选框。、
目标检测分类
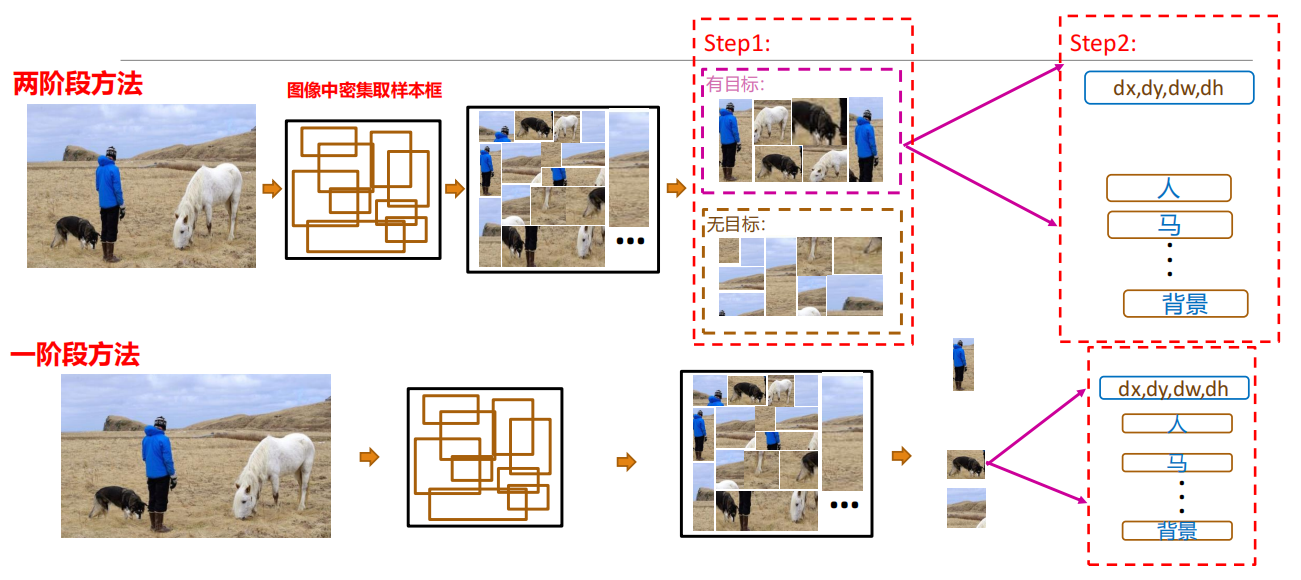
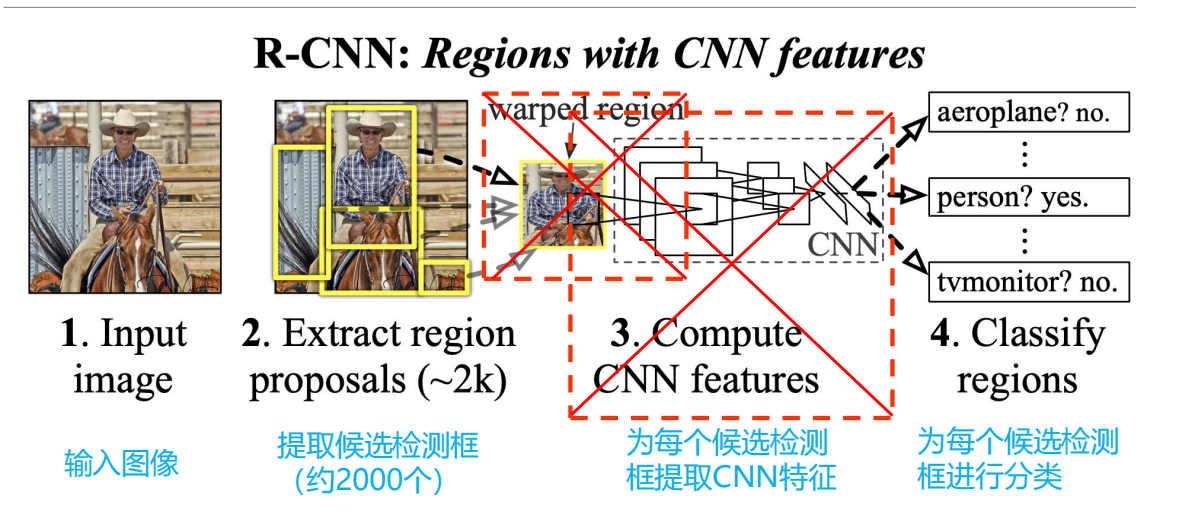
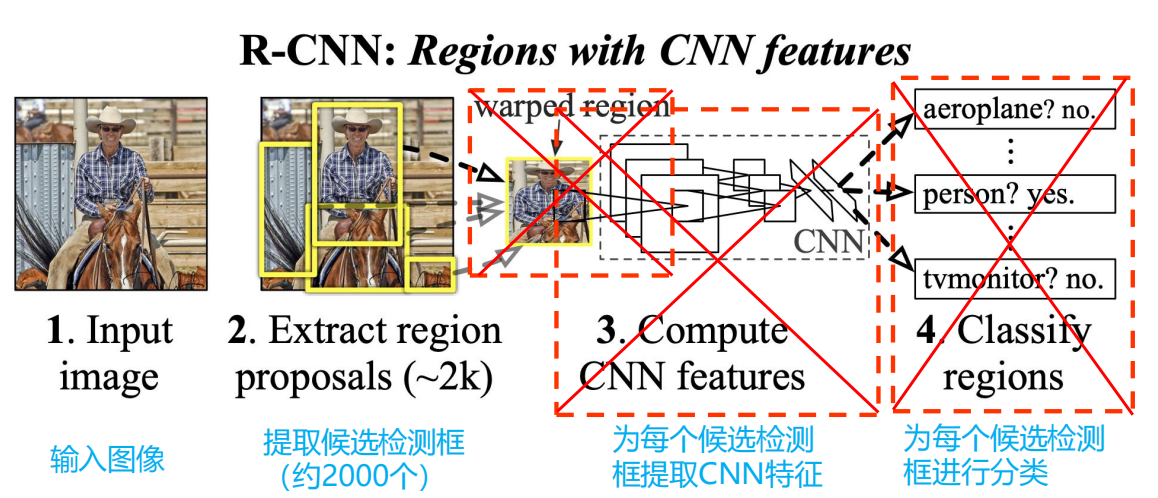
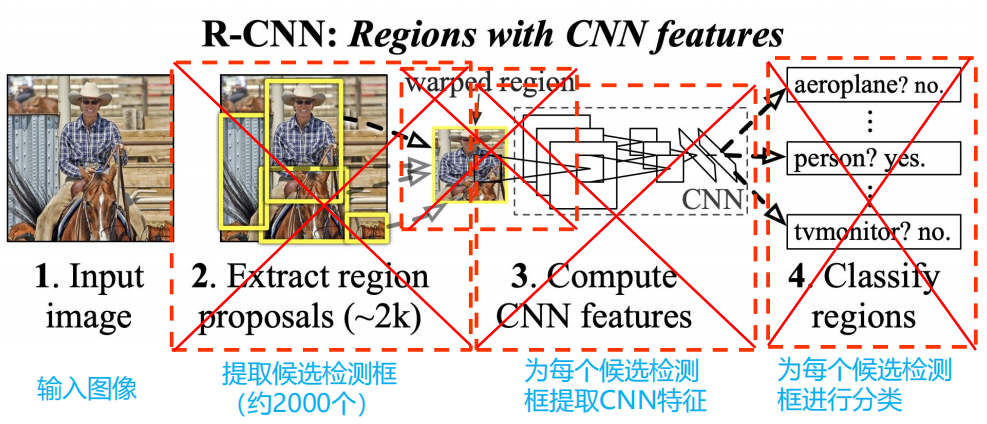
R-CNN
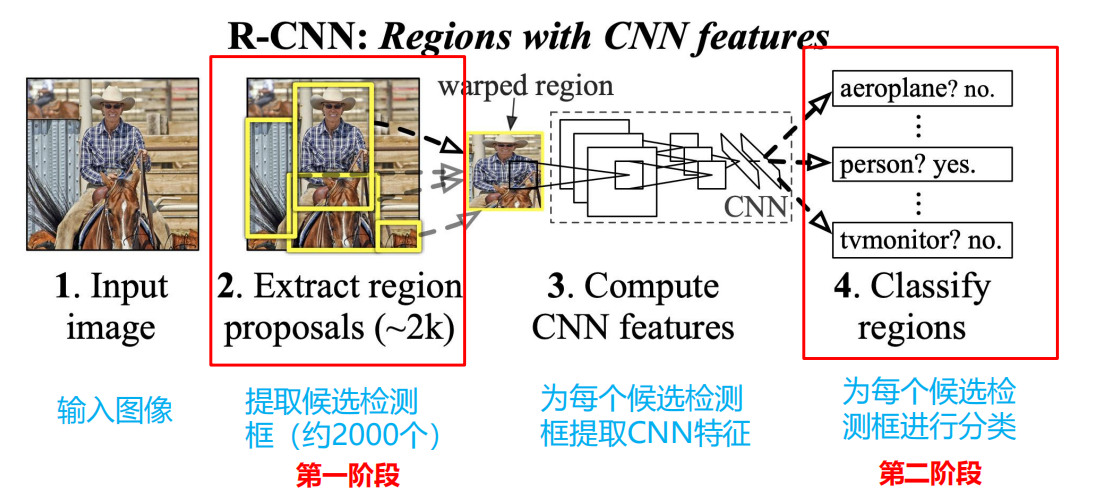
存在的问题是什么呢?
对于每张图像,还需要额外的步骤提取region proposal;存储和重复地提取每个region proposal的特征花费大量的存储和计算资源;全连接层需要固定输入维度,因此需要确保输入到网络的图像尺寸一致。
区域拉伸

使用warped region(区域拉伸):就是上图中的红色边框,为了与CNN兼容,R-CNN直接将所有的候选区域统一到了227*227的尺寸。但是存在的问题就是:将每个region proposal统一成同样的尺寸,严重影响CNN提取特征的质量。
特征提取
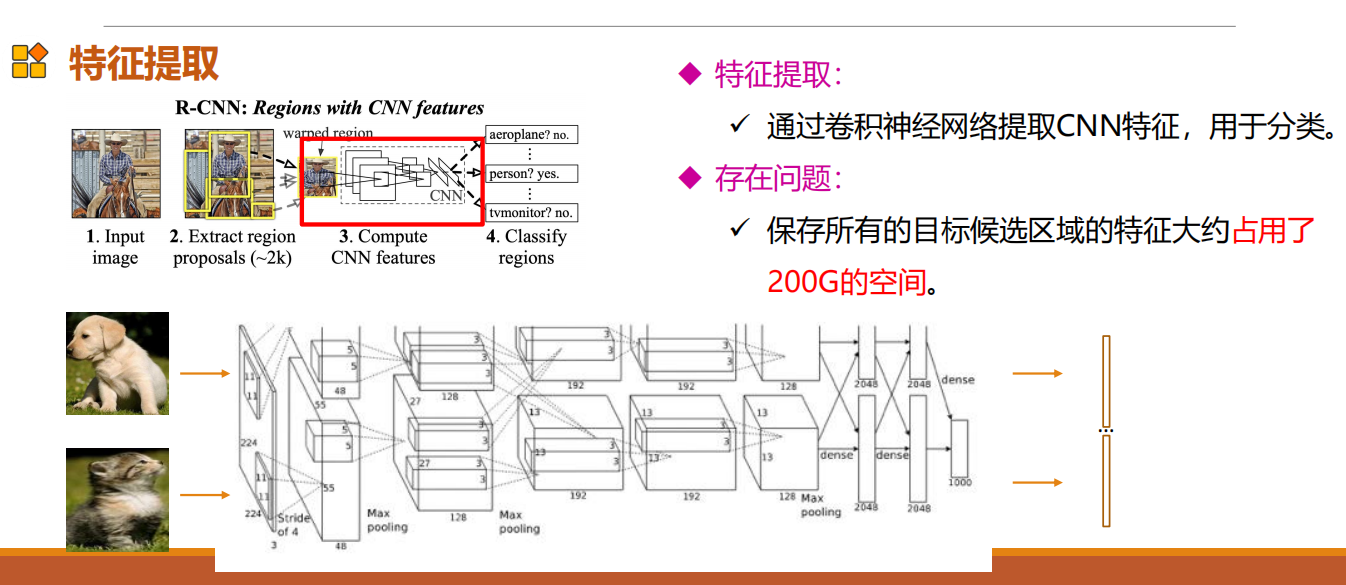
对于下一个问题,存储和重复地提取每个region proposal的特征花费大量的存储和计算资源,保存所有的目标候选区域的特征大约占用了200G的空间。
区域分类

边框界回归
SPP-Net
提取特征

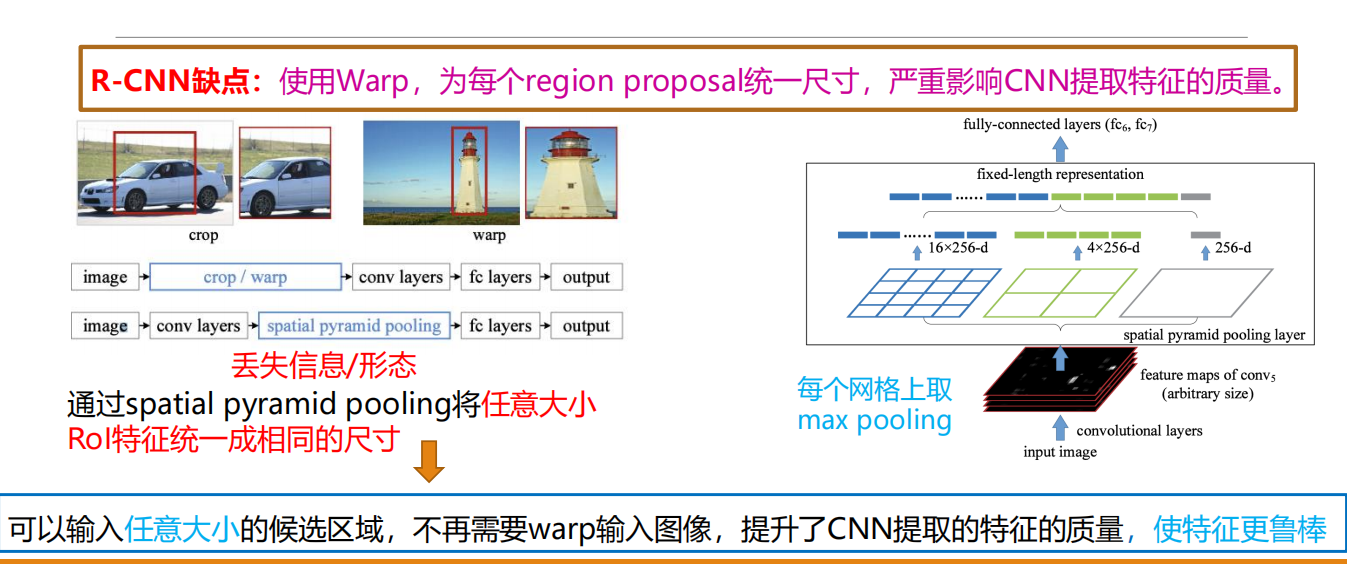
池化方式为空间金字塔池化
Fast R-CNN
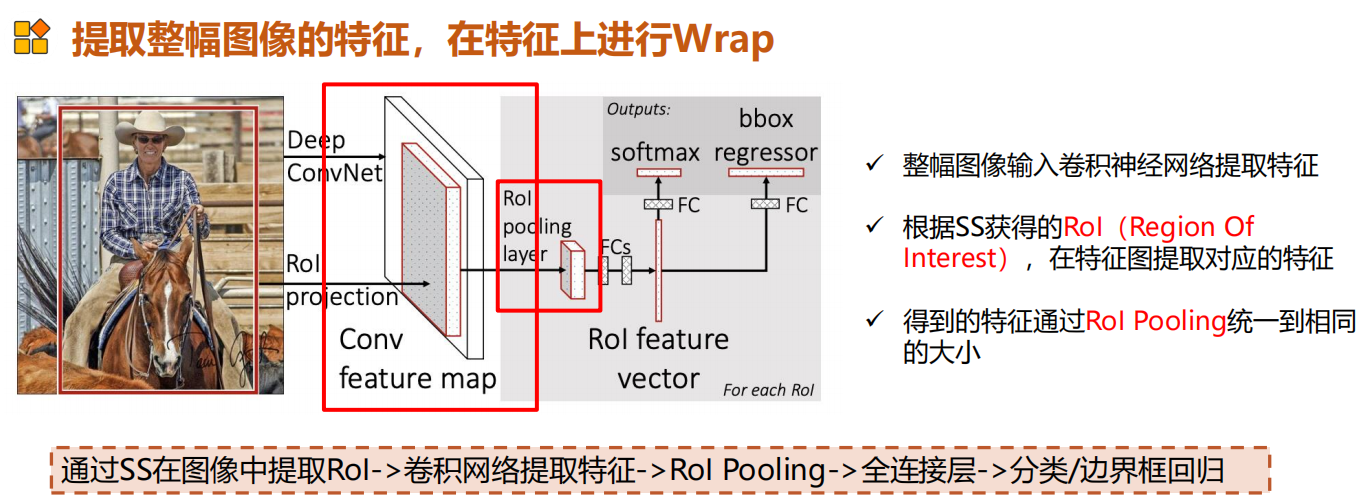
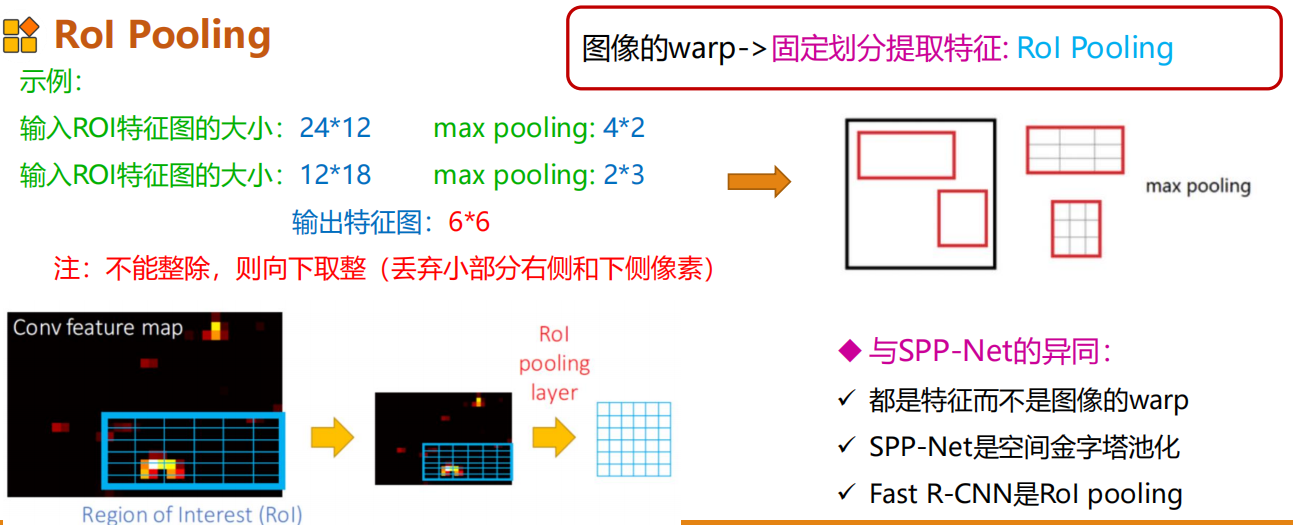
池化方式为Rol pooling
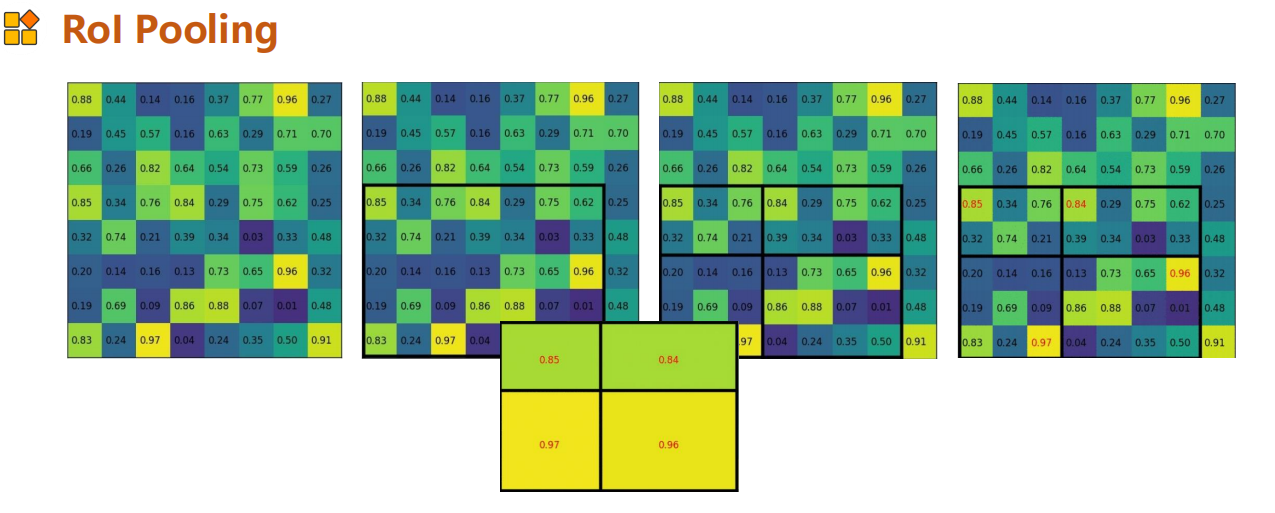
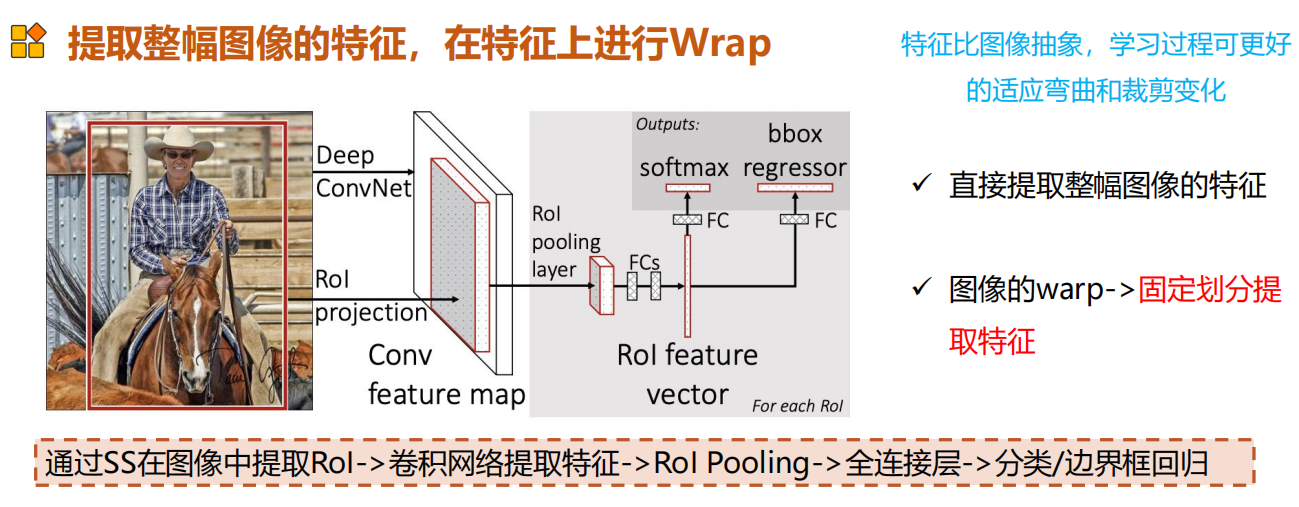
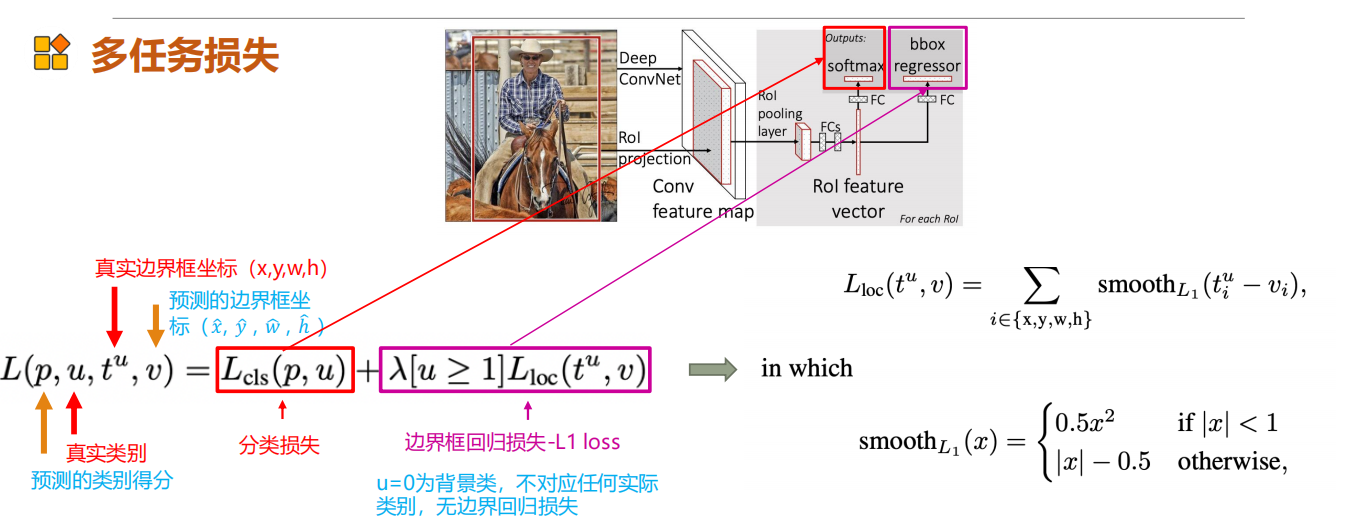
总的来说相当于直接提取图像的特征,将图片的warp改为固定划分提取特征。
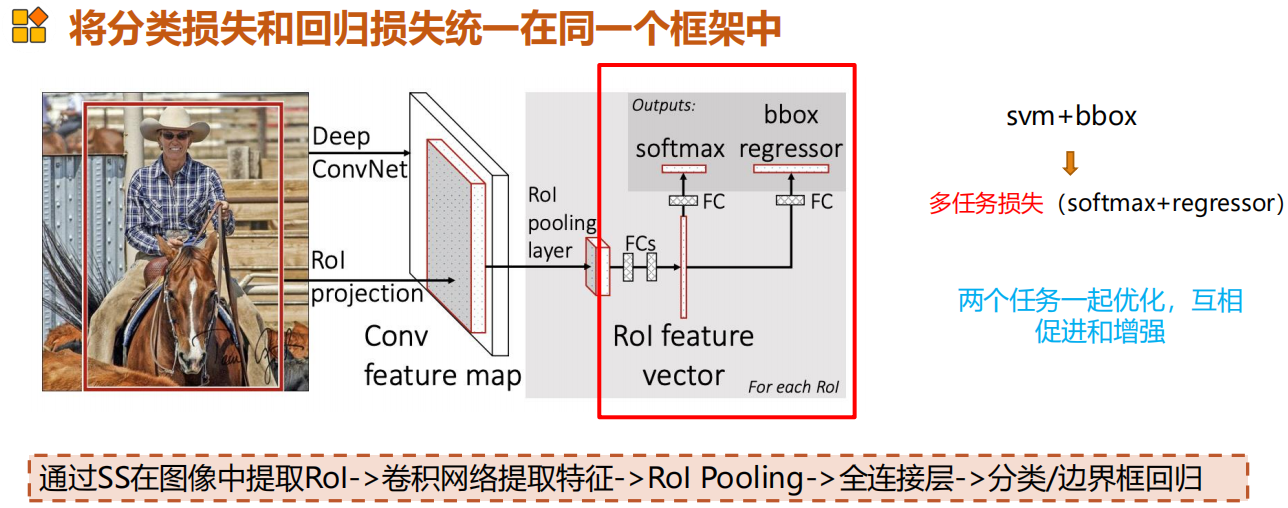
损失函数的设计有两个,将回归和分类都用在了一个任务中。
损失函数设计
Faster R-CNN
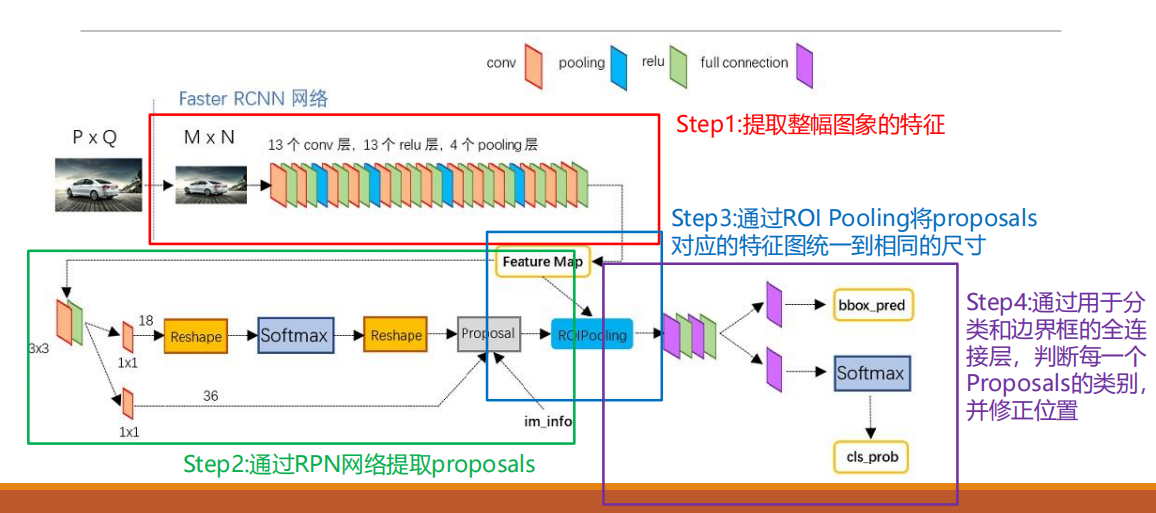
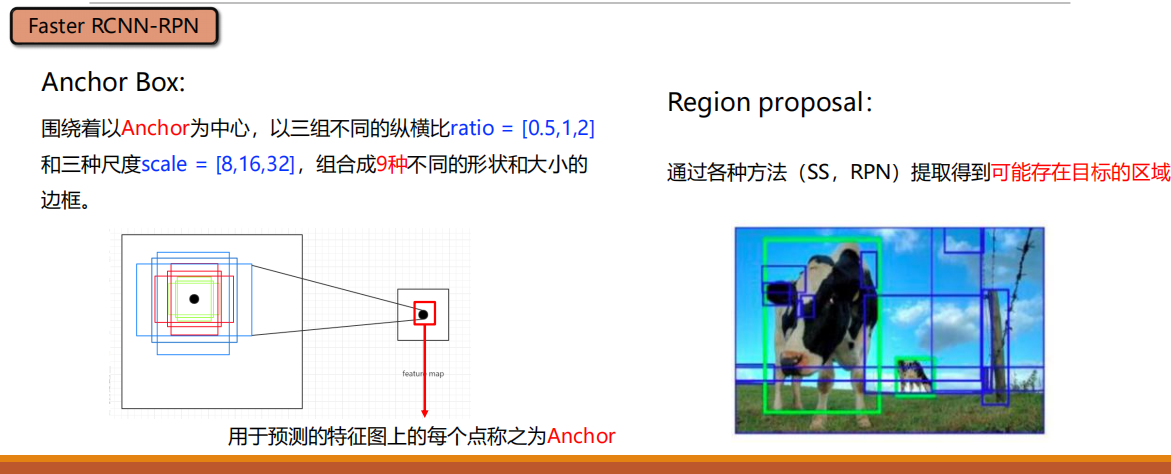
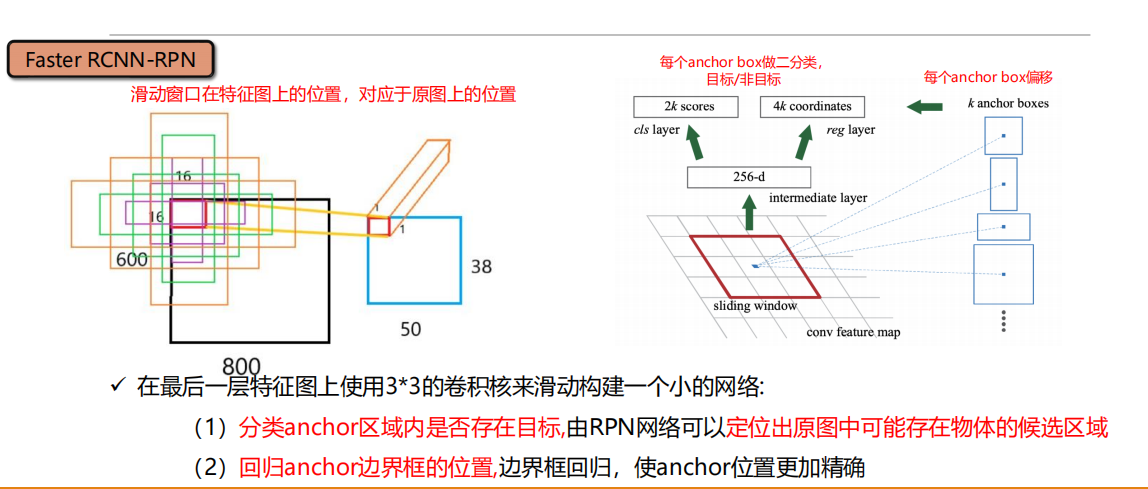


所有的检测过程被统一到了一个网络之中。
本章课件来自百度松果



