
机器学习教程六:线性回归预测波士顿房价
sklearn.linear_model.LinearRegression
参数
我们先来看看sklearn中的对线性回归的定义,官网链接

sklearn.linear_model.LinearRegression是scikit-learn库中的线性回归模型类。它实现了普通最小二乘法(Ordinary Least Squares,OLS)来拟合线性模型,并最小化实际观测目标与线性近似预测目标之间的残差平方和。
参数解释:
-
fit_intercept(布尔型,默认为True):指定是否计算模型的截距。如果设置为False,则计算过程中不使用截距,即假设数据已经中心化。 -
copy_X(布尔型,默认为True):指定是否复制输入特征矩阵X。如果设置为True,会对X进行拷贝,否则可能会直接修改原始数据。 -
n_jobs(整数型,默认为None):指定计算过程中使用的并行作业数量。仅在问题足够大时(即n_targets > 1并且X是稀疏的,或者positive设置为True)才能提供加速效果。默认值为None,表示使用1个作业,除非在joblib.parallel_backend上下文中。-1表示使用所有处理器。 positive(布尔型,默认为False):当设置为True时,强制系数为正。这个选项仅适用于密集数组。
所以重要的点就是第一个,使用默认值为True,其它的参数保持为默认参数即可。
方法
下面我们来看看这个类中实现了哪些方法:

fit(X, y[, sample_weight]):拟合线性模型。接受特征矩阵X和目标变量y作为输入,并使用最小二乘法拟合线性模型。可选参数sample_weight用于指定样本的权重。get_metadata_routing():获取该对象的元数据路由,用于元数据传递。get_params([deep]):获取该估计器的参数。可选参数deep控制是否返回嵌套参数。predict(X):使用线性模型进行预测。接受特征矩阵X作为输入,并返回预测的目标变量值。score(X, y[, sample_weight]):返回预测结果的决定系数(coefficient of determination)。接受特征矩阵X和目标变量y作为输入,可选参数sample_weight用于指定样本的权重。set_fit_request(*[, sample_weight]):设置用于拟合方法的元数据请求。该函数用于请求传递给fit()方法的元数据。set_params(**params):设置该估计器的参数。接受关键字参数params,用于更新估计器的参数。set_score_request(*[, sample_weight]):设置用于评估方法的元数据请求。该函数用于请求传递给score()方法的元数据。
所以真正重要的方法就是fit()、predict()和score(),记住这三个即可。你可能会问,为什么会有score()函数呢,回归不是只有损失函数吗?分类才有score()函数呀,其实这个score()计算的不是分类的结果,通关观察源码,你可以看到它的计算方式为:1-(残差平方和/总平方和)。不看源码还真的不知道呀。
波士顿房价预测:最小二乘法的方式
数据集介绍
在sklearn1.0版本中,波士顿数据集已经被弃用了,也就是不能直接通过方法进行加载,让我们简单八卦一下:在原本中说到,波士顿房价存在一个伦理问题,数据集作者假设种族自我隔离对房价有积极影响;此外数据集存在一个没有证明的数据,也就是数据有一个特征不可信。
这怎么办呢,聪明的你是不是想到换一个数据集???没错,我们换一个库来调用波士顿房价预测数据集,数据集直达链接。我们可以使用numpy库提供的函数进行加载。我们看到前22行是介绍,进行删除,下面的数据,奇数行有11个,偶数行有3个,需要分别加载,然后拼接到一起。
给出下面加载的代码。
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston" #波士顿数据集网站
#sep是正则表达式,匹配任意空白字符;前22行是数据集介绍,进行跳过;没有列标题,header=None
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
#奇数行和偶数行分开,然后拼接到一起
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
print(data.shape)
target = raw_df.values[1::2, 2]
print(target.shape)最后我们可以看到data.shape是(506,13),target.shape是(506),表示数据集中有506个样本,每个样本有13个特征。
简单介绍一下数据集,前13行表示特征,最后一行是标签。
切分数据集
使用sklearn.model_selection导入train_test_split()函数对数据集进行切分,训练集用来训练,测试集用来测试得分。我们使用下面代码导入数据集并进行切分。
from sklearn.model_selection import train_test_split
train_data, test_data, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)从上面来看,我们导入了data数据集和target标签,并按照测试集0.2比例进行切分,但是random_state=42是什么鬼。
如果你问我,我会告诉你这是宇宙的终极形态(doge)。这源自于英国作家道格拉斯·亚当斯的科幻系列小说《银河系漫游指南》(The Hitchhiker’s Guide to the Galaxy)。在这个系列的故事中,超级计算机Deep Thought被问到生命、宇宙和一切的终极问题,其答案是“42”。这个答案成为了一个流行的文化符号,经常在计算机科学和编程社区中被引用和玩味。只能说:浪漫的程序员,男人至死是少年。这个值的作用是设置随机种子,使得结果可以复现。
使用模型
首先创建模型,并进行训练。
from sklearn.linear_model import LinearRegression
model= LinearRegression(fit_intercept=True) #设置模型有偏置
model.fit(train_data, train_target) #对模型进行训练
y_pred = model.predict(test_data)
#计算均方差损失
print(f"均方差损失(MSE): {mean_squared_error(test_target, y_pred)}")这样我们成功得到了模型,并使用模型对测试集进行了评估,得到了均方差损失,如下图所示。

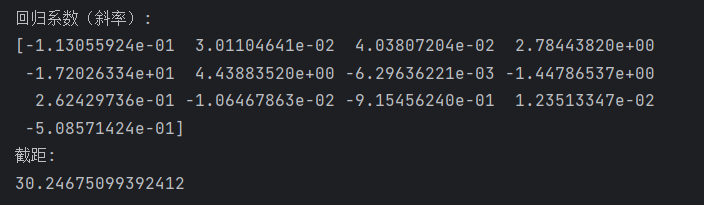
查看一下模型的斜率和截距:
# 查看回归系数(斜率)
print("回归系数(斜率):")
print(model.coef_)
# 查看截距
print("截距:")
print(model.intercept_)如下图所示:
完整代码见:huahai2022/mechine-learning: 机器学习理论+实战,KNN、贝叶斯、回归、决策树等,入门级教程 (github.com)
波士顿房价预测:使用梯度下降算法的方式(pytorch)
加载数据集并进行处理
和前面的处理大致相同,但是添加对数据的标准化,将每个特征值的均值为0,标准值1。上面不能做数据标准化,因为要用原始数据做最小二乘计算。
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
data_url = "http://lib.stat.cmu.edu/datasets/boston" #波士顿数据集网站
#sep是正则表达式,匹配任意空白字符;前22行是数据集介绍,进行跳过;没有列标题,header=None
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
print(data.shape)
target = raw_df.values[1::2, 2]
print(target.shape)
# 数据标准化
scaler = StandardScaler()
data = scaler.fit_transform(data)
#将数据集拆分为训练集和测试集
train_data, test_data, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
# 转换为张量
X_train = torch.Tensor(train_data)
X_label = torch.Tensor(train_target)
y_train = torch.Tensor(test_data)
y_label = torch.Tensor(test_target)
编写网络进行识别
使用均方差损失函数作为损失函数,使用SGD随机梯度下降来作为优化器。
import torch
import torch.nn as nn
import torch.optim as optim
class Net(nn.Module): #为保证和上面最小二乘法的网络一致,使用一个全连接层
def __init__(self):
super(Net, self).__init__()
self.fc = nn.Linear(13, 1)
def forward(self, x):
x = self.fc(x)
return x
model = Net()
criterion = nn.MSELoss() #均方差损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01) #随机梯度下降
num_epochs = 1000
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_train)
print(outputs.shape)
loss = criterion(outputs, X_label)
# 反向传播和优化
optimizer.zero_grad() #梯度清零
loss.backward() #计算梯度,保存在grad中
optimizer.step() #调整参数值
# 打印每个epoch的损失
if (epoch + 1) % 10 == 0:
print(f'Epoch {epoch + 1}/{num_epochs}, Loss: {loss.item():.4f}')
with torch.no_grad():
predicted = model(y_train)
print('Predicted values:', predicted)
#均方差损失
mse = criterion(predicted, y_label)
print('Mean Squared Error:', mse.item())进行1000个周期训练之后,我们看到均方差为:

可以看到这种方法不一定比最小二乘法好,但是我的模型非常简单,只有1层,神经网络相信大力出奇迹,果然名不虚传。
完整代码见[github](huahai2022/mechine-learning: 机器学习理论+实战,KNN、贝叶斯、回归、决策树等,入门级教程 (github.com))





