
机器学习教程七:逻辑回归算法原理
逻辑回归简介
逻辑回归用于解决二分类或多分类问题,它通过建立一个逻辑函数(如Sigmoid函数)来建模目标变量的概率分布,将线性组合的结果映射到一个介于0和1之间的概率值。这个概率值可以用于判断样本属于两个类别中的哪一个或多个。
逻辑回归的输出是一个概率值,可以根据选择的阈值将概率转化为二分类或多分类的预测结果。通常,当概率大于阈值时,样本被分为正类别;当概率小于阈值时,样本被分为负类别。
使用情景
作为一个分类算法,当然可以解决二分类问题,比如:垃圾邮件分类;逻辑回归可以扩展到解决多分类问题。一种常见的方法是使用一对多(One-vs-Rest)策略,将多类别分类问题转化为多个二分类问题,每个类别都训练一个二分类逻辑回归模型,然后通过比较预测的概率值来确定最终的类别;逻辑回归可以输出样本属于某个类别的概率值,例如广告点击率预测。
逻辑回归是回归吗?
尽管带有”回归“二字,但是我们通过上面的了解,可以看出逻辑回归不是回归,它其实是一种分类算法,用来解决分类问题。
回归和分类的区别?见附录
逻辑回归原理
我的理解就是逻辑回归和线性回归的本质是一样的,但是在输出上稍微有些区别。在方程上,逻辑回归也可以写成y=xw+b的形式,但是通过最后一步添加非线性函数,将线性回归转变成了一个分类问题。对于二分类问题,我们通常使用sigmoid函数作为非线性函数。
z表示线性回归的结果,g(z)相当于对线性回归的结果添加了sigmod函数。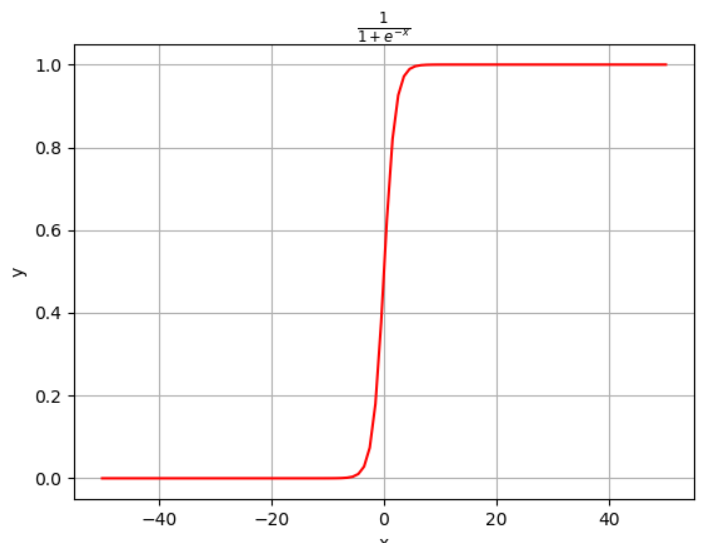
这是sigmoid的图形,可以看到它将连续的回归数值转变成了一个概率值,也就是分类任务。
我们就得到了预测函数:
对于我们的分类任务有:
我们直到对于标签y=1来说,函数只保留了h~$\theta$~,我们想要这个值尽可能大,表示模型的确信度越大;对于标签y=0来说,函数保留了(1-h~$\theta$~),我们想要它的值尽可能大,表示模型的确信度也越大。下面就是想办法把上面式子的总体尽可能大。
似然函数:我们让上面式子总体大,可以把他们乘在一起,结果尽可能大也是一样的。
要求这个最大值,我们转化为对数似然。
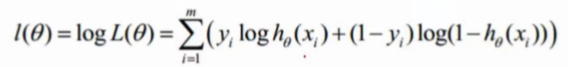
通常情况下,我们求最大值转换为求最小值,引入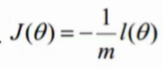 转换为梯度下降任务。m表示样本的总数,一个样本贡献1/m的力量。
转换为梯度下降任务。m表示样本的总数,一个样本贡献1/m的力量。
下面就是对对数似然估计进行求导。
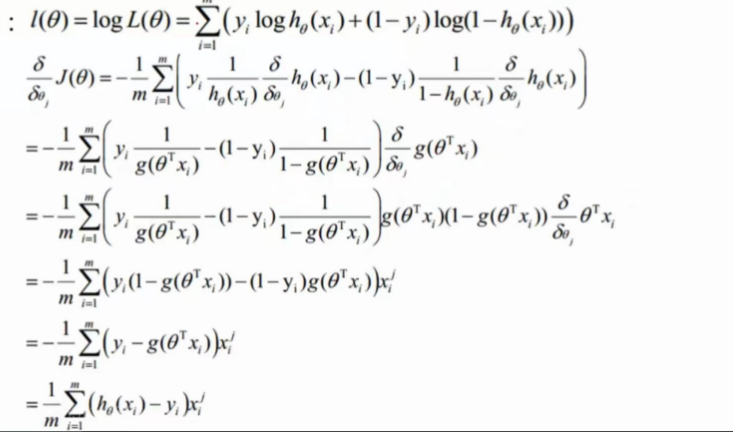
我们想到对数似然值变小,我们要把这个参数往梯度下降的方向更新,参数更新公式是:
其中$alpha$表示学习率,后面部分表示梯度,不断更新参数,达到分类的目的。
多分类问题
当然,更复杂的问题可能有:
现在是分成两类,如果数据需要分成三类或者更多该怎么办?
假如有A、B、C三类,把其中A类做为1,BC做为0,然后做Logistic regression,得到模型a,同理将B类做为1,AC作为0,得到模型b,再同理得到模型c。最后测试的时候,对任意一个数据点x, 我们能够得到x分别属于A、B、C三类的概率值。最后比较大小,哪个大,这个x就属于哪一类。
当然,我们有更好地方法,更好地方法就是更换非线性函数,使用softmax函数作为分类函数。它的函数如下所示:
总的来说它是等于单个样本结果的指数除以所有样本结果的指数的求和。就是下面的图来表示:(图来自《一天搞懂深度学习》)
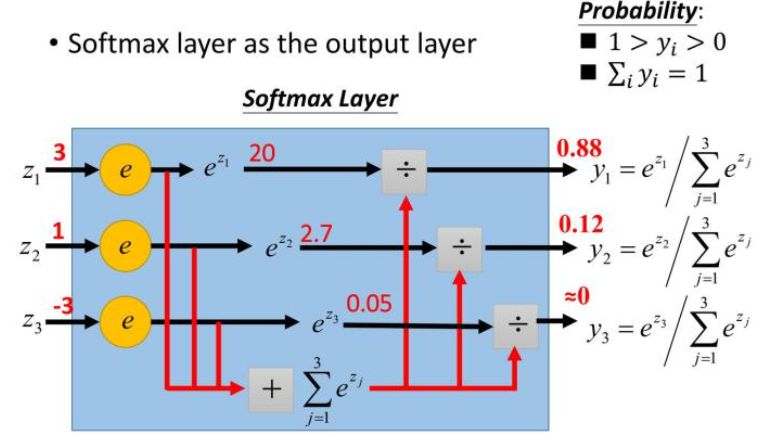
为什么这个地方要使用这个方法呢,或者说为什么要引入e,不直接除以呢。
和逻辑回归的sigmod函数一样,使用最大化对数训练模型,可以很好的通过对数消除指数。
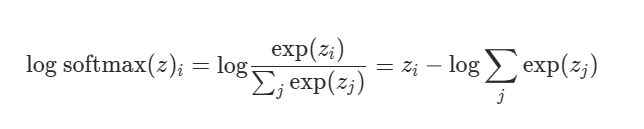
第二点是,softmax的总概率为1,所以可以看作是各个神经元竞争的方式,与此同时,使用指数,让大的更大,小的更小,有一种惩恶扬善的意思。
优缺点
优点:
- 简单高效:逻辑回归是一种相对简单的算法,计算效率高,训练速度快。
- 可解释性强:逻辑回归给出的结果是概率值,可以被解释为样本属于某个类别的概率,易于理解和解释。
- 可以处理高维数据:逻辑回归在处理高维特征数据时表现良好,适用于特征空间较大的问题。
- 可以进行概率预测:逻辑回归模型可以输出样本属于不同类别的概率,而不仅仅是简单的分类结果。
缺点:
- 线性决策边界:逻辑回归的决策边界是线性的,对于复杂的非线性关系可能表现不佳。在处理非线性问题时,需要通过特征工程或引入多项式特征等方法来扩展特征空间。
- 对异常值敏感:逻辑回归对异常值敏感,异常值的存在可能会对模型的性能产生较大影响。
- 容易欠拟合:当特征之间的关系不是简单的线性关系时,逻辑回归可能会出现欠拟合的情况,无法很好地拟合数据。所以有多层感知机
附录
回归和分类
回归和分类是机器学习中两种不同的任务类型,通常有一下区别:
- 任务类型:
- 回归:回归问题旨在预测连续型的目标变量。在回归任务中,我们试图建立一个模型,根据输入的特征来预测一个连续的输出值。例如,预测房价、销售额等连续的数值。
- 分类:分类问题旨在将样本分到不同的类别中。在分类任务中,我们试图建立一个模型,根据输入的特征来预测样本所属的类别。例如,将电子邮件分类为垃圾邮件或非垃圾邮件、将图像分类为猫或狗等。
- 输出类型:
- 回归:回归任务的输出是连续型的数值,可以是整数或实数。回归模型通过学习特征与目标变量之间的关系,预测出一个数值。
- 分类:分类任务的输出是离散型的类别标签。分类模型通过学习特征与类别之间的关系,将样本划分到不同的类别中。
- 模型:
- 回归:回归问题可以使用线性回归、支持向量机回归(SVM)、KNN、决策树回归、随机森林回归等模型进行建模和预测。
- 分类:分类问题可以使用逻辑回归、决策树分类、支持向量机分类(SVM)、KNN、随机森林分类、神经网络等模型进行建模和预测。
- 评估指标:
- 回归:常用的回归评估指标包括均方误差(Mean Squared Error, MSE)、均方根误差(Root Mean Squared Error, RMSE)、平均绝对误差(Mean Absolute Error, MAE)等,用于衡量预测值与真实值之间的误差。
- 分类:常用的分类评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值等,用于衡量模型的分类性能。
在上面的模型上,我们看到决策树,支持向量机等算法既可以用来做决策,又可以用来做回归,这个怎么理解呢,拿我们目前学过的KNN来举例,对于分类问题,KNN使用训练集中的特征和标签构建一个特征空间,然后对于新的未知样本,在特征空间中找到其K个最近邻居(根据某种距离度量),并根据这K个邻居的标签进行多数投票或权重投票来确定新样本的类别。对于回归问题,KNN同样使用训练集中的特征和标签构建特征空间。对于新的未知样本,KNN找到其K个最近邻居,并根据这K个邻居的标签(或目标值)的平均值来估计新样本的目标值。所以我们可以使用KNN分类算法,把未知样本归于某类;也可以使用KNN作为回归算法,为未知样本打上目标值。





