
机器学习教程三:决策树算法
决策树简介
决策树是一种基于树状结构的机器学习算法,用于解决分类和回归问题。它通过构建一棵树来进行决策,其中每个内部节点表示一个特征或属性,每个叶子节点表示一个类别或一个回归值。决策树在机器学习和数据挖掘领域广泛应用,具有直观、易于理解和解释的特点。
最早的决策树算法之一是ID3(Iterative Dichotomiser 3),由Ross Quinlan于1986年提出。ID3算法使用信息增益来选择最佳的特征,并通过递归地构建决策树来进行分类。后来,C4.5算法作为ID3的改进版本出现。C4.5在选择最佳特征时使用了信息增益比,解决了ID3算法对具有更多取值的特征的偏好问题,并引入了对缺失数据的处理方法。此外,CART(Classification and Regression Trees)算法是另一个常用的决策树算法。CART算法可以处理分类和回归问题,并使用基尼系数来选择最佳的特征。
决策树算法的发展还引入了剪枝技术,用于防止决策树过拟合训练数据。剪枝技术可以通过修剪决策树的节点或子树来提高模型的泛化能力。
使用情景
我们来举个例子,假设我们有一个二分类问题,要根据一个人的一些特征来预测他们是否会购买某个产品。
特征:
- 年龄:青年、中年、老年
- 收入:低、中等、高
- 学历:初中、高中、大学以上
| 序号 | 年龄 | 收入 | 学历 | 购买产品 | |
|---|---|---|---|---|---|
| 1 | 青年 | 中等 | 高中 | 否 | |
| 2 | 中年 | 低 | 初中 | 否 | |
| 3 | 中年 | 低 | 大学以上 | 是 | |
| 4 | 老年 | 低 | 大学以上 | 是 | |
| 5 | 老年 | 高 | 高中 | 否 | |
| 6 | 中年 | 中等 | 大学以上 | 是 | |
| 7 | 青年 | 中等 | 高中 | 否 | |
| 8 | 青年 | 低 | 初中 | 否 | |
| 9 | 老年 | 中等 | 大学以上 | 是 | |
| 10 | 老年 | 高 | 高中 | 是 |
我们可以画出下面的决策树
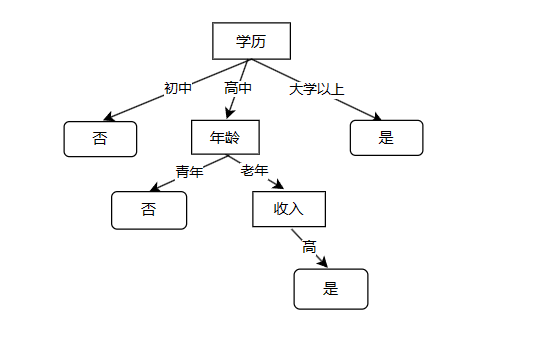
在上面图中直角矩形表示特征,也是内部节点;带弧角的矩形表示分类结果,也是叶子节点。你可能会有疑问,这个决策树怎么画出来的呢,为什么要把学历放到最上面的节点呢?我们下面来说一说决策树构建的过程。
决策树原理
决策树的原理基于对特征的分裂和划分,通过对样本的特征值进行逐层比较,根据特征的取值将样本划分到不同的分支上。这个过程基于一系列的判断条件,使得样本在决策树上向叶子节点逐步推进,最终得到样本的分类结果。
实现决策树需遵循下面的步骤:
1、准备数据集:收集需要用于训练和测试的数据集。数据集包含输入特征和相应的标签或目标值。
2、选择特征:根据问题的要求,从数据集中选择最佳的特征作为决策树的根节点。通常使用特征选择算法来评估特征的重要性,例如信息增益、基尼系数等。
3、划分数据集:根据选择的特征,将数据集划分为不同的子集,使得每个子集具有相似的特征。
4、递归构建决策树:对于每个子集,递归地重复步骤 2 和 3,选择最佳的特征来构建子树,直到满足停止条件为止。停止条件可能是所有样本属于同一类别,或者到达预定义的树的深度。
6、预测和分类:使用生成的决策树对新的输入样本进行分类。从根节点开始,根据样本的特征值,沿着树的分支进行遍历,直到到达叶子节点,然后将样本分配到叶子节点所代表的类别。
1.准备数据集
我们对数据的属性进行标注。对于年龄属性:1表示青年,2表示中年,3表示老年;对于收入属性:1表示低,2表示中等,3表示高;对于学历属性:1表示初中,2表示高中,3表示大学以上;对于是否购买产品:使用0表示否,1表示是。
使用代码进行表示:
def createDataset():
myDataset = [[1, 2, 2, 0],
[2, 1, 1, 0],
[2, 1, 3, 1],
[3, 1, 3, 1],
[3, 3, 2, 0],
[2, 2, 3, 1],
[1, 2, 2, 0],
[1, 1, 1, 0],
[3, 2, 3, 1],
[3, 3, 2, 1]]
# 最后一列表示标签,0表示未购买产品,1表示购买产品
labels=["年龄", "收入", "学历", "是否购买产品"]
return myDataset,labels
if __name__ == '__main__':
myDataset,labels = createDataset()这样我们就使用代码表示了这个数据集,下一步我们将进行特征选择。
2.选择特征
为了将不同类别分开,我们需要选择特征,特征选择不到位,我们可能构建出效率低或者错误率搞得决策树。在我们上面的决策树的图中,为什么要首先选择“学历”这个特征呢,如何选择特征呢?
常用的特征选择方法是信息增益(Information Gain),基于信息论的概念,衡量了一个特征对于分类任务的贡献程度。信息增益越高,表示特征提供的信息量越大,对于分类任务的贡献也越大。
计算信息增益,需要遵循下面的步骤:
1.计算整体数据集的熵
2.计算每个特征的条件熵
3.计算信息增益
2.1计算整体数据集的熵
在高中化学,我们学过,熵用来衡量物体的混乱程度,熵越大,物体越混乱。熵在信息中定义为信息的期望值,对于一个数据集中一个待分类的类别,它的熵怎么计算呢?答案是下面公式
在这个公式中,p(xi)表示类别xi在数据集中出现的概率,所以类别xi的熵相当于它的概率乘以“-log2(p(xi))”,你可能想问这个值是怎么来的,我只能告诉你因为1+1=2,这个也是一样的,是老一代程序员的定义,它的贡献就是将信息具体化,用数值表示出来。
上面我们只得到一个类别的熵,要计算整体数据集的熵,我们只需要对每个类别的熵进行求和,我们应该有下面公式:
其中数据集中有n个类别,每个类别出现概率为p(xi)。
所以我们来计算上面例子的熵,有一半人购买产品,一半人未购买产品。对于购买产品的一类,p(x1)=1/2,对于未购买产品的一类,p(x2)=1/2。所以它的数据集的信息熵就是:
我们成功计算出来数据集的熵是1,下面我们编写代码来计算数据集的熵。
import math
def createDataset():
myDataset = [[1, 2, 2, 0],
[2, 1, 1, 0],
[2, 1, 3, 1],
[3, 1, 3, 1],
[3, 3, 2, 0],
[2, 2, 3, 1],
[1, 2, 2, 0],
[1, 1, 1, 0],
[3, 2, 3, 1],
[3, 3, 2, 1]]
# 最后一列表示标签,0表示未购买产品,1表示购买产品
labels=["年龄", "收入", "学历", "是否购买产品"]
return myDataset,labels
def calculate_entropy(dataset):
#使用class_counts记录各个标签样本的数量
class_counts = {}
for data in dataset:
label = data[-1]
if label not in class_counts:
class_counts[label] = 0
class_counts[label] += 1
entropy = 0
total_samples = len(dataset)
#计算数据集的熵
for count in class_counts.values():
probability = count / total_samples
entropy -= probability * math.log2(probability)
return entropy
if __name__ == '__main__':
myDataset,labels = createDataset()
print(f"数据集的熵为{calculate_entropy(myDataset)}")可以看到最后的熵,和我们计算的一致。

2.2计算每个特征的条件熵
下面我们计算每个特征的条件熵,先来说说什么是条件熵,条件熵用于衡量在给定条件下的随机变量的不确定性。它表示在已知某个条件的情况下,对随机变量的平均不确定性。
给定一个随机变量X和条件随机变量Y,条件熵H(X|Y)表示在已知Y的条件下,X的不确定性。它的计算公式如下:
我们已经确定了在Y的条件下,这个Y就对应与上面的三个特征,就是年龄、收入和学历;xi表示的是在选定某个特征下面的分类类别,比如说在特征年龄下面分出来三个类别;p(xi)表示的在特征值选定时各类别出现的概率,比如在特征年龄下,青年的概率为3/10,中年的概率为3/10,老年的概率为4/10;H(X|Y=xi)则表示当特征为某个特征值时的熵,比如年龄这个特征为老年时,有3/4的购买产品,有1/4的不购买产品,那么这个时候特征为老年的熵就是:
所以我们可以计算出各个特征的条件熵。我们将特征记为Y,在Y下面的所有类别记为X,则可以计算各个特征的条件熵。
H(X|Y=学历)=\frac{2}{10}*(-\frac{2}{2}*log_2\frac{2}{2})+\frac{4}{10}*(-\frac{3}{4}*log_2\frac{3}{4}-\frac{1}{4}*log_2\frac{1}{4})+\frac{4}{10}*(-\frac{4}{4}*log_2\frac{4}{4})
根据上面的分析结果,我们可以写出计算特征条件熵的代码,相对来说比较绕,理解过程很重要:
import math
def createDataset():
myDataset = [[1, 2, 2, 0],
[2, 1, 1, 0],
[2, 1, 3, 1],
[3, 1, 3, 1],
[3, 3, 2, 0],
[2, 2, 3, 1],
[1, 2, 2, 0],
[1, 1, 1, 0],
[3, 2, 3, 1],
[3, 3, 2, 1]]
# 最后一列表示标签,0表示未购买产品,1表示购买产品
labels=["年龄", "收入", "学历", "是否购买产品"]
return myDataset,labels
def calculate_condition_entropy(dataset, feature_index):
feature_counts = {} #用于统计各个特征以及对应标签的出现次数
for row in dataset:
feature = row[feature_index]
label = row[-1]
if feature not in feature_counts: #初始化为字典的嵌套,0表示未购买产品,1表示购买产品
feature_counts[feature] = {0: 0, 1: 0}
feature_counts[feature][label] += 1
#得到对应特征的统计信息,比如第二列的统计信息为{2: {0: 2, 1: 2}, 1: {0: 2, 1: 2}, 3: {0: 1, 1: 1}}
entropy = 0
dataset_len=len(dataset) #数据集的总长度
for feature in feature_counts:
counts=sum(feature_counts[feature].values()) #统计特征出现的次数
conditional_entropy=0
probability=counts/dataset_len #计算特征出现的概率
for label in feature_counts[feature]:
conditional_probability=feature_counts[feature][label]/counts #在特征固定时,用来计算标签的概率
conditional_entropy-=conditional_probability*math.log2(conditional_probability) if conditional_probability!=0 else 0 #计算条件熵
entropy+=probability*conditional_entropy #条件熵的加权平均
return entropy #返回总熵值
if __name__ == '__main__':
myDataset,labels = createDataset()
print(calculate_condition_entropy(myDataset, 0))2.3计算信息增益
我们前面已经说了,信息增益越大,对特征的最终的分类结果影响也越大,那么就是分别计算各个特征的信息增益。那么信息增益怎么计算呢,相信聪明的你一定想到了,信息增益就是熵减去条件熵。
可以看到单个特征的信息增益g(X,Y=年龄)等于H(X)数据集的熵减去H(X|Y=年龄)单个特征的条件熵。代码很简单,就是一个减法。
def calculate_entropy(dataset):
#使用class_counts记录各个标签样本的数量
class_counts = {}
for data in dataset:
label = data[-1]
if label not in class_counts:
class_counts[label] = 0
class_counts[label] += 1
entropy = 0
total_samples = len(dataset)
#计算数据集的熵
for count in class_counts.values():
probability = count / total_samples
entropy -= probability * math.log2(probability)
return entropy
def createDataset():
myDataset = [[1, 2, 2, 0],
[2, 1, 1, 0],
[2, 1, 3, 1],
[3, 1, 3, 1],
[3, 3, 2, 0],
[2, 2, 3, 1],
[1, 2, 2, 0],
[1, 1, 1, 0],
[3, 2, 3, 1],
[3, 3, 2, 1]]
# 最后一列表示标签,0表示未购买产品,1表示购买产品
labels=["年龄", "收入", "学历", "是否购买产品"]
return myDataset,labels
def calculate_condition_entropy(dataset, feature_index):
feature_counts = {} #用于统计各个特征以及对应标签的出现次数
for row in dataset:
feature = row[feature_index]
label = row[-1]
if feature not in feature_counts: #初始化为字典的嵌套,0表示未购买产品,1表示购买产品
feature_counts[feature] = {0: 0, 1: 0}
feature_counts[feature][label] += 1
#得到对应特征的统计信息,比如第二列的统计信息为{2: {0: 2, 1: 2}, 1: {0: 2, 1: 2}, 3: {0: 1, 1: 1}}
entropy = 0
dataset_len=len(dataset) #数据集的总长度
for feature in feature_counts:
counts=sum(feature_counts[feature].values()) #统计特征出现的次数
conditional_entropy=0
probability=counts/dataset_len #计算特征出现的概率
for label in feature_counts[feature]:
conditional_probability=feature_counts[feature][label]/counts #在特征固定时,用来计算标签的概率
conditional_entropy-=conditional_probability*math.log2(conditional_probability) if conditional_probability!=0 else 0 #计算条件熵
entropy+=probability*conditional_entropy #条件熵的加权平均
return entropy #返回总熵值
if __name__ == '__main__':
myDataset,labels = createDataset()
#特征1的信息增益
print(f"特征一的信息增益是{calculate_entropy(myDataset)-calculate_condition_entropy(myDataset,0)}")
#特征2的信息增益
print(f"特征二的信息增益是{calculate_entropy(myDataset)-calculate_condition_entropy(myDataset,1)}")
#特征3的信息增益
print(f"特征三的信息增益是{calculate_entropy(myDataset)-calculate_condition_entropy(myDataset,2)}")得到下面的结果
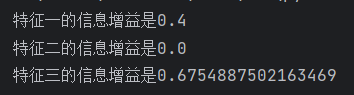
可以看到我们应该先选择特征3,这便是我们最有价值的特征。
3.划分数据集
我们选择出了特征3,然后我们根据特征3来划分数据集。给出下面的代码:
def splitDataset(dataset, feature_index, value):
"""
:param dataset: 数据集
:param feature_index: 选择的特征
:param value: 特征的label
:return: 切分后的数据集
"""
retDataset = []
for row in dataset:
if row[feature_index]== value: #选择特征,如果特征是某个值的话,就把该特征以及该特征后面的特征组成新的子集
subDataset=row[:feature_index].extend(row[feature_index+1:])
retDataset.append(subDataset)
return retDataset这样我们根据特征3可以将原始数据集分为下面数据集
myDataset = [[1, 2, 2, 0],
[2, 1, 1, 0],
[2, 1, 3, 1],
[3, 1, 3, 1],
[3, 3, 2, 0],
[2, 2, 3, 1],
[1, 2, 2, 0],
[1, 1, 1, 0],
[3, 2, 3, 1],
[3, 3, 2, 1]]
sliptedDataset = [[1, 2, 0], #特征3的值为2
[3, 3, 0],
[1, 2, 0],
[3, 3, 1]]
[[2, 1, 0], #特征3的值为1
[1, 1, 0],
[[2, 1, 1], #特征3的值为3
[3, 1, 1],
[2, 2, 1],
[3, 2, 1]]4.递归构建决策树
我们使用ID3来递归构建决策树,ID3算法的基本思想是通过选择具有最大信息增益的特征来构建决策树。每次选择完特征,数据集的熵要改变,然后重新计算剩下特征的条件增益,继续选择特征,直到选择完所有的特征,不可再分。或者特征不足以分类出所有类别,即特征全部选择完毕,不可再分。下面给出完整代码:
import math
import operator
def calculate_entropy(dataset):
# 使用class_counts记录各个标签样本的数量
class_counts = {}
for data in dataset:
label = data[-1]
if label not in class_counts:
class_counts[label] = 0
class_counts[label] += 1
entropy = 0
total_samples = len(dataset)
# 计算数据集的熵
for count in class_counts.values():
probability = count / total_samples
entropy -= probability * math.log2(probability)
return entropy
def createDataset():
myDataset = [[1, 2, 2, 0],
[2, 1, 1, 0],
[2, 1, 3, 1],
[3, 1, 3, 1],
[3, 3, 2, 0],
[2, 2, 3, 1],
[1, 2, 2, 0],
[1, 1, 1, 0],
[3, 2, 3, 1],
[3, 3, 2, 1]]
# 最后一列表示标签,0表示未购买产品,1表示购买产品
labels=["年龄", "收入", "学历", "是否购买产品"]
return myDataset,labels
def calculate_condition_entropy(dataset, feature_index):
feature_counts = {} # 用于统计各个特征以及对应标签的出现次数
for row in dataset:
feature = row[feature_index]
label = row[-1]
if feature not in feature_counts: # 初始化为字典的嵌套,0表示未购买产品,1表示购买产品
feature_counts[feature] = {0: 0, 1: 0}
feature_counts[feature][label] += 1
# 得到对应特征的统计信息,比如第二列的统计信息为{2: {0: 2, 1: 2}, 1: {0: 2, 1: 2}, 3: {0: 1, 1: 1}}
entropy = 0
dataset_len = len(dataset) # 数据集的总长度
for feature in feature_counts:
counts = sum(feature_counts[feature].values()) # 统计特征出现的次数
conditional_entropy = 0
probability = counts / dataset_len # 计算特征出现的概率
for label in feature_counts[feature]:
conditional_probability = feature_counts[feature][label] / counts # 在特征固定时,用来计算标签的概率
conditional_entropy -= conditional_probability * math.log2(
conditional_probability) if conditional_probability != 0 else 0 # 计算条件熵
entropy += probability * conditional_entropy # 条件熵的加权平均
return entropy # 返回总熵值
def split_dataset(dataset, feature_index, value):
"""
:param dataset: 数据集
:param feature_index: 选择的特征
:param value: 特征的label
:return: 切分后的数据集
"""
retDataset = []
for row in dataset:
if row[feature_index] == value: # 选择特征,如果特征是某个值的话,就把该特征以及该特征后面的特征组成新的子集
subDataset = row[:feature_index]
subDataset.extend(row[feature_index + 1:])
retDataset.append(subDataset)
return retDataset
def choose_best_feature_to_split(dataset):
"""
:param dataset: 数据集
:return: 最佳特征的索引
"""
feature_dim = len(dataset[0]) - 1 # 数据集中的特征维度
entroy = calculate_entropy(dataset) # 计算数据集的熵
best_feature_gain = {} # 使用字典存储特征的增益
for i in range(feature_dim): # 计算每个特征的信息增益
gain = calculate_entropy(dataset) - calculate_condition_entropy(dataset, i)
best_feature_gain[i] = gain
max_value = max(best_feature_gain.values()) # 返回最大的信息增益的维度
max_keys = [key for key, value in best_feature_gain.items() if value == max_value]
return max_keys[0]
def majority_cnt(class_list):
# 返回类别中出现次数最多的类别
class_count = {}
for vote in class_list:
if vote not in class_count.keys():
class_count[vote] = 0
class_count[vote] += 1
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
return sorted_class_count[0][0]
def create_decision_tree(dataset,labels,feature_labels):
"""
:param dataset: 数据集
:return: 决策树
"""
class_list = [row[-1] for row in dataset] # 获取数据集的类别
if class_list.count(class_list[0]) == len(class_list): # 如果类别完全相同则停止划分
return class_list[0]
if len(dataset[0]) == 1: # 如果所有特征都遍历完了,则停止划分
return majority_cnt(class_list)
best_feature = choose_best_feature_to_split(dataset)
best_feature_label = labels[best_feature]
labels.remove(best_feature_label)
feature_labels.append(best_feature_label)
my_tree={best_feature_label:{}}
feature_values=set([row[best_feature] for row in dataset])
for value in feature_values:
sub_labels=labels[:]
sub_dataset=split_dataset(dataset,best_feature,value)
my_tree[best_feature_label][value]=create_decision_tree(sub_dataset,sub_labels,feature_labels)
return my_tree
if __name__ == '__main__':
myDataset,labels = createDataset()
print(create_decision_tree(myDataset,labels,[]))得到下面的结果:

可以看到先按照学历分,然后按照年龄,最后按照收入,但是存在一个问题,那就是数据量不足,分到最后,学历为2,年龄为3,收入为3的应该有两位,一位购买了产品,一位未购买产品,但是数据量不足,最总没有分出来。
5.预测和分类
构建predict函数,很简单,就是不断取特征,直到结果能分出来。下面是完整代码。
def predict(decision_tree, sample):
if isinstance(decision_tree, dict):
for feature in decision_tree:
value = sample.get(feature)
if value in decision_tree[feature]:
subtree = decision_tree[feature][value]
return predict(subtree, sample)
return None
else:
return decision_tree
if __name__ == '__main__':
myDataset,labels = createDataset()
decision_tree=create_decision_tree(myDataset,labels,[])
print(decision_tree)
test_dataset =[{'学历': 2, '年龄': 3, '收入': 3},{'学历': 3, '年龄': 1, '收入': 3}]
print(f"{test_dataset[0]}的决策结果为{predict(decision_tree, test_dataset[0])}")
print(f"{test_dataset[1]}的决策结果为{predict(decision_tree, test_dataset[1])}")得到下面的结果:

完整代码已上传到github仓库
决策树特点
优点:
- 可解释性强:决策树的生成过程可以直观地表示为一系列的决策规则,易于理解和解释。
- 适用性广泛:决策树可以用于分类和回归任务,适用于离散特征和连续特征,也可以处理多分类和多输出问题。
- 数据预处理要求低:相对于其他算法,决策树对数据的预处理要求较低。它可以处理缺失值和不完整的数据,并且对于不平衡的数据集也比较鲁棒。
缺点:
- 容易过拟合:决策树容易生成过于复杂的模型,对训练数据过拟合,导致在新数据上的泛化能力下降。剪枝等技术可以缓解过拟合问题。
- 不稳定性:对于数据的微小变化,决策树可能生成完全不同的树结构,这使得模型的稳定性较差。
- 忽略特征间的相关性:决策树独立地考虑每个特征的重要性,可能忽略了特征之间的相关性,导致模型的性能下降。
- 对不平衡数据集的处理困难:决策树在处理不平衡数据集时,倾向于选择具有更多类别样本的特征,可能忽略少数类别的重要性。





